
HTTP篇
HTTP
HTTP(HyperText Transfer Protocol)即超文本传输协议,是一种获取网络资源的应用层协议,它是互联网数据通信的基础,由请求和响应构成。
URI和URL
URI
- URI(Uniform Resource Identifier)即统一资源标识符,用于标识某个互联网资源,由熟悉的URL和URN构成
- URL(Uniform Resource Locator)即统一资源定位符,俗称网址。应用程序通过URL才能定位到资源所处的位置,URL相当于一个人的住址
- URN(Uniform Resource Name)即统一资源名称,是URI过去的名字,用于在特定的命名空间中标识资源,URN相当于一个人的身份
URL语法
- URL有两种表现方式:绝对和相对。
HTTP协议
HTTP协议有三个特征,如下:
持久连接
管道化
状态管理
HTTP报文
HTTP报文就是HTTP协议通信的内容,HTTP报文是一种简单的格式化数据块,由带语义的纯文本组成,所以能很方便地进行读或写。
报文语法
报文分为两类:请求报文和响应报文
请求报文由五部分组成:请求方法、请求URL、HTTP协议版本、可选的请求首部和内容
响应报文由五部分组成:HTTP协议版本、状态码、原因短语、可选的响应首部和内容
请求方法
HTTP协议通过请求方法说明请求目的,期望服务器执行某个操作。常用的请求方法如下:
| 方法 | 功能 |
|---|---|
| GET | 获取数据 |
| POST | 提交数据 |
| PUT | 上传文件 |
| DELETE | 删除文件 |
| HEAD | 获取除了内容以外的资源信息 |
状态码

1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
- 「200 OK」是最常见的成功状态码,表示一切正常。如果是非
HEAD请求,服务器返回的响应头都会有 body 数据。 - 「204 No Content」也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。
- 「206 Partial Content」是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
- 「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
HTTP首部
HTTP首部提供的信息能让客户端和服务器执行指定的操作。首部的类型如下:
通用首部
通用首部既可以存在于请求中,也可以存在于响应中。
| 首部 | 描述 |
|---|---|
| Connection | 管理持久连接 |
| Date | 报文的创建日期,HTTP协议使用了特殊的日期格式 |
| Transfer-Encoding | 传输报文主体时的编码方式,例如分块传输编码 |
请求首部
请求首部存在于请求报文中,提供客户端的信息以及对服务器的要求。
| 首部 | 描述 |
|---|---|
| Accept | 可接收的MIME类型 |
| Accept-Charset | 可接收的字符集 |
| Accept-Encoding | 可接收的编码格式,服务器按指定的编码格式压缩数据 |
| Accept-Language | 可接收的语言种类 |
| Host | 服务器域名和端口 |
| Referer | 上一个页面地址 |
| User-Agent | 用户代理信息,例如操作系统、浏览器名称和版本等 |
MIME类型就是媒体类型
响应首部
响应首部只存在于响应报文中
| 首部 | 描述 |
|---|---|
| Accept-Ranges | 服务器接收的范围类型 |
| Server | 服务器软件的名称和版本 |
| Age | 响应存在时间,单位为秒,这个首部可能由代理发出 |
实体首部
请求和响应都可能包含实体首部,实体首部提供了大量的实体信息。
| 首部 | 描述 |
|---|---|
| Content-Encoding | 内容编码格式,告知客户端用这个编码格式解压 |
| Content-Language | 内容语言 |
| Content-Length | 内容尺寸,单位是字节 |
| Content-Type | 内容的MIME类型 |
扩展首部(自定义首部)
缓存
Web缓存可以自动将资源副本保存到本地,减少了客户端与服务器之间的通信次数,加速页面加载,降低网络延迟。
缓存的处理过程可以简单地分为几步,首先在缓存中搜索指定资源的副本,如果命中就执行第二步;第二步就是对资源进行新鲜度检验(就是文档是否过期),如果不新鲜就执行第三步;第三步是与服务器进行新鲜度再检验,验证通过就更新资源副本的新鲜度,再返回这个资源副本,不通过就是服务器返回资源,再将最新资源的副本放入缓存中。
新鲜度检验
日期对比法进行新鲜度再验证
实体标记法进行新鲜度再验证
通信原理
HTTP通信需要操作系统建立HTTP层下面的TCP连接通道,所有的文本数据都是通过这些TCP通道接收和发送,这个通道是使用socket建立的。
程序伪代码:

原理:先在80端口监听,然后进入无限循环,若有请求过来,就接受(accept),创建新的socket,最后通过这个socket来接收、发送HTTP数据。
HTTP/2.0
HTTP/2.0是HTTP/1.1的扩展版本,主要基于SPDY协议,引入了全新的二进制分帧层,保留了1.1版本的大部分语义,例如请求方法、状态码和首部等,由互联网工程任务组(IETF)为2.0版本实现标准化。
HTTP/1.1有很多不足,如下:
在传输中会出现队首阻塞问题
响应不分轻重缓急,只会按先来后到的顺序去执行
并行通信需要建立多个TCP连接
服务器不能主动推送客户端想要的资源,只能被动地等待客户端发起请求
由于HTTP是无状态的,所以每次请求和响应都会携带大量的冗余信息
二进制分帧层
二进制分帧层是HTTP/2.0性能增强的关键。
流、消息和帧是二进制分帧层的基本概念,如下:
| 概念 | 描述 |
|---|---|
| 流 | 一个可以承载双向消息的虚拟信道,每个流都有一个唯一的整数标识符 |
| 消息 | HTTP消息,即HTTP报文 |
| 帧 | 通信的最小单位,保存着不同类型的数据,例如HTTP首部、资源优先级、配置信息等 |
每个帧都有一个首部,包含帧的长度、类型、标志、流标识符和保留位,如下:
一帧最多带24位长度的数据,也就是16MB,这个长度不包括首部内容
8位的类型用于确定帧的格式和语义,帧的类型有DATA、HEADERS和PRIORITY等
8位的标志允许不同类型的帧定义自己独有的消息标志
1位的保留字段(R),语义未定义,始终设置为0
31位的流标识符用于标识当前帧属于哪条数据流
多路复用
HTTP/2.0不但解决了队首阻塞的问题,还将TCP建立连接次数降低到只有1次。通信两端只需将消息分解为独立的帧,然后在多条数据流中乱序发送,最后在接收端把帧重新组合成消息,并且各条消息的组合互不干扰,这就实现了真正意义上的并行通信,达到了多路复用的效果。
请求优先级
在HTTP/2.0中,每条数据流都有一个31位的优先值,值越小优先级越大(0的优先级最高)。
服务器推送
HTTP/2.0支持服务器主动推送,简单地说就是一次请求返回多个响应,这也是一种减少请求的方法。服务器除了处理最初的请求外,还会额外推送客户端想要的资源,无须客户端发出明确的请求。主动推送的资源不但可以被缓存,而且还能被压缩,客户端也可以主动拒绝推送过来的资源。
首部压缩
HTTP是无状态的,为了准确地描述每次通信,通常都会携带大量的首部,例如Connection、Accept或者Cookie
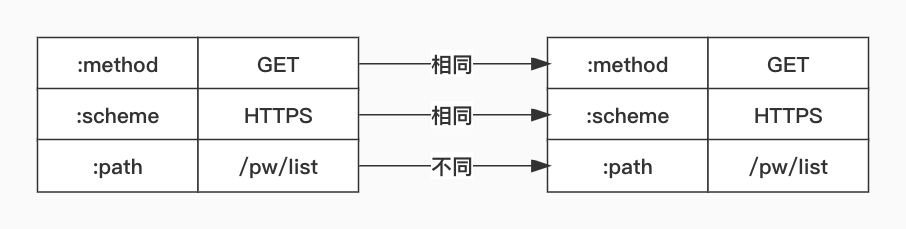
,而这些首部会消耗上百甚至上千字节的带宽。为了降低这些开销,HTTP/2.0会先用HPACK算法压缩首部,然后再进行传输。HPACK算法会让通信两端各自维护一张首部字典表,其中包含了首部名和首部值(如下图所示),其中首部名要全部小写,并用伪首部表示,例如::method、:host或:path。每次请求都会记住已发哪些首部,下一次只需传输差异的数据,相同的数据只需传索引就行。
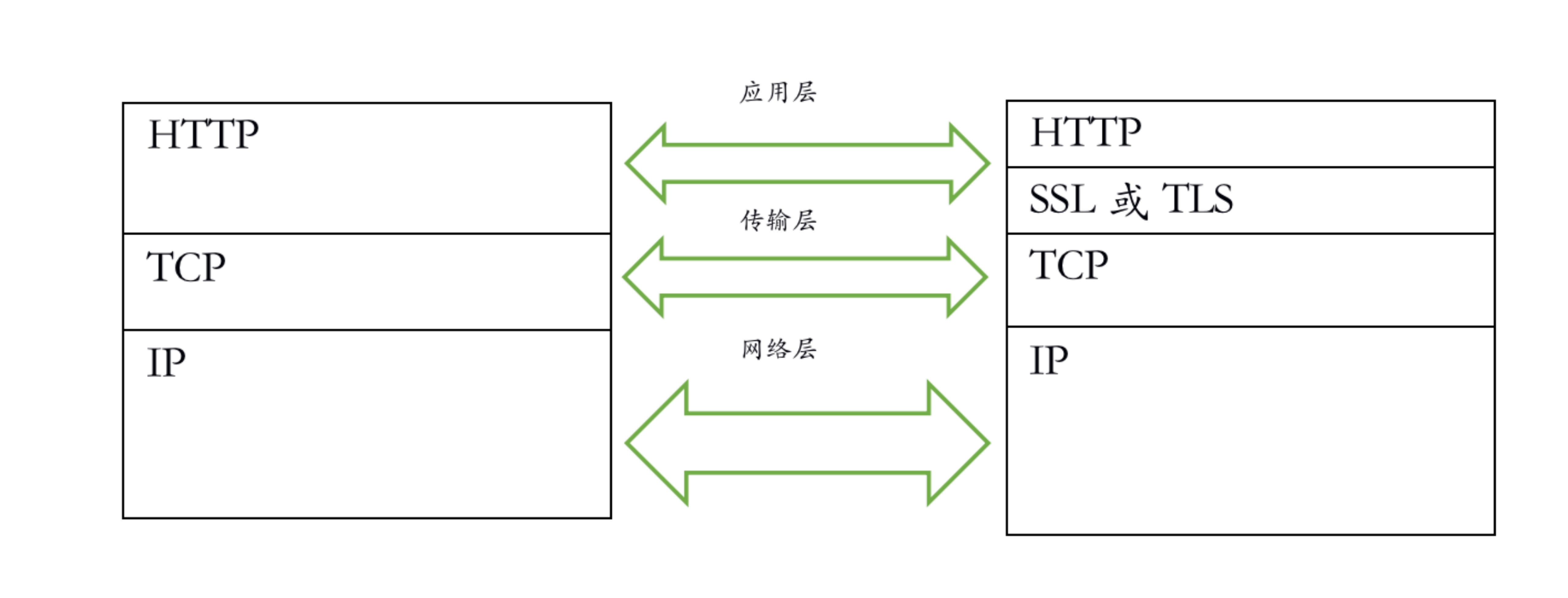
HTTPS
HTTPS(HTTP Secure)是一种构建在SSL或TLS上的HTTP协议,简单地说,HTTPS是HTTP的安全版本。SSL(Secure Sockets Layer)及其继任者TLS(Transport Layer Security)是一种安全协议,为网络通信提供来源认证、数据加密和报文完整性检测,以保证通信的保密性和可靠性。
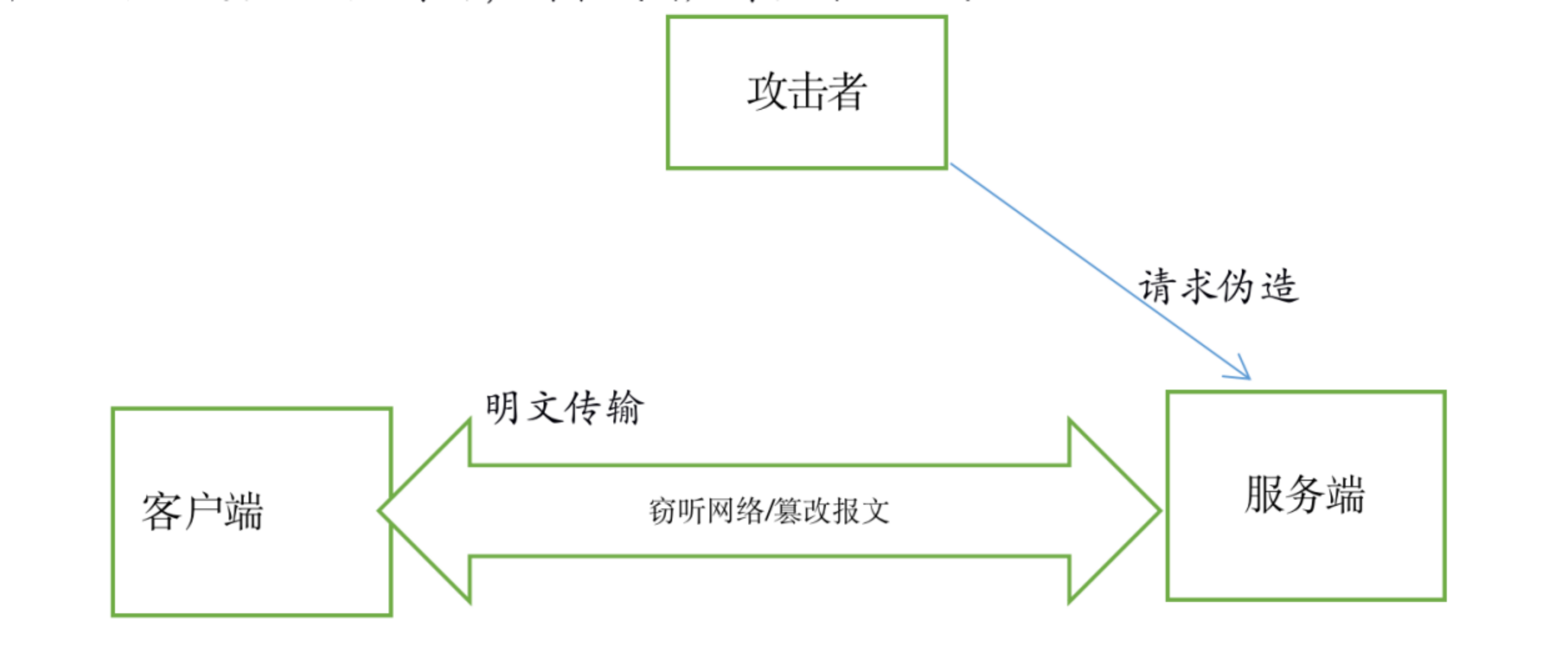
之所以会说HTTP不安全,是由于以下原因造成的
数据以明文传递,有被窃听的风险
接收到的报文无法证明是发送时的报文,不能保证完整性,因此报文有被篡改的风险
不验证通信两端的身份,请求或响应有被伪造的风险
加密
在密码学中,加密是指将明文转换为难以理解的密文;解密与之相反,把密文换回明文。加密和解密都有两部分组成:算法和秘钥。加密算法可以分为两类:对称加密和非对称加密。
- 对称加密
对称加密在加密和解密的过程中只使用一个秘钥,这个秘钥称为对称秘钥(Symmetric Key),也称为共享秘钥。对称秘钥的优点是计算速度快,缺点是通信两端需要分享秘钥。客户端和服务端在进行对话前,要先将对称秘钥发送给对方,在传输的过程中秘钥有被窃取的风险,一旦被窃取,那么密文就能被翻译成明文,加密保护形同虚设。
- 非对称加密
非对称加密在加密的过程中使用公开密钥(Public Key),在解密的过程中使用私有秘钥(Private Key)。加密和解密的过程也可以反过来,使用私有秘钥加密,再用公开密钥解密。非对称加密的特点是计算速度慢,但它很好地解决了对称加密的问题,避免了信息泄露。通信两端若都使用非对称加密,那么各自都会生成一对秘钥,私钥留在身边,公钥发送给对方,公钥在传输途中即使被人窃取,也不用担心,因为没有私钥就无法轻易解密。在交换好公钥后,就可以用对方的公钥把数据加密,开始密文对话。
注意:HTTPS采用混合加密机制,在交换公钥阶段使用非对称加密,在传输报文阶段使用对称加密。
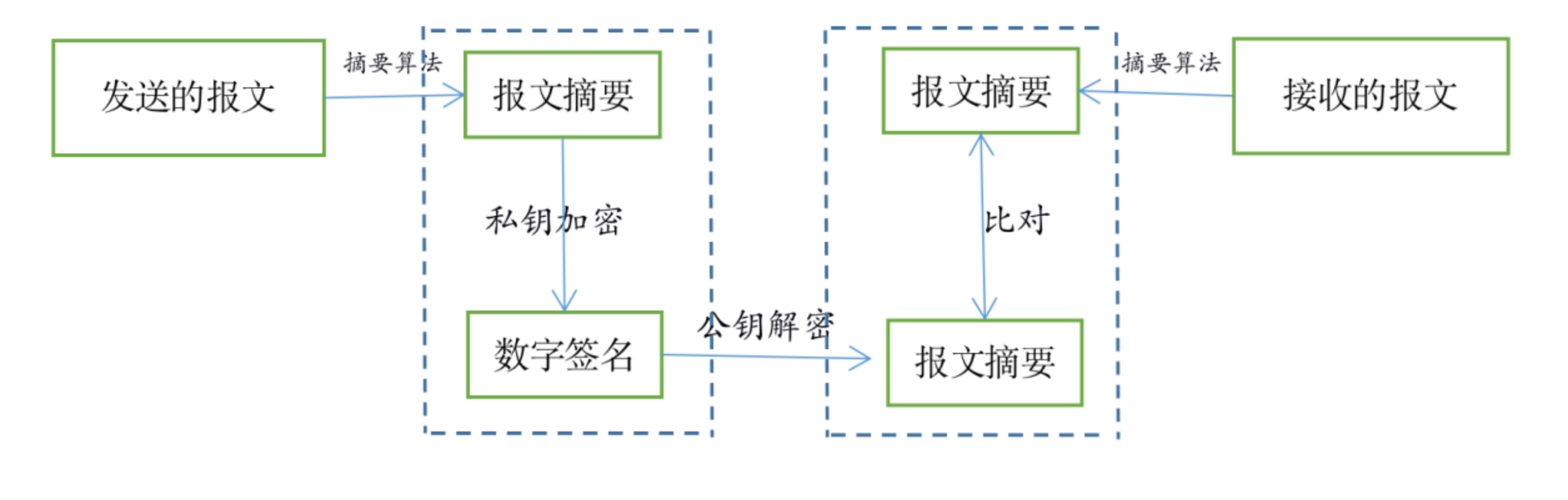
数字签名
数字签名是一段由发送者生成的特殊加密校验码,用于确定报文的完整性。数字签名的生成涉及两种技术:非对称加密和数字摘要。数字摘要可以将变长的报文提取为定长的摘要,报文内容不同,提取出的摘要也将不同,常用的摘要算法由MD5和SHA。签名和校验的过程分为以下五步:
发送方用摘要算法对报文进行提取,生成一段摘要
然后用私钥对摘要进行加密,加密后的摘要作为数字签名附加在报文上,一起发送给接收方
接收方收到报文后,用同样的摘要算法提取出摘要
再用接收到的公钥对报文中的数字签名进行解密
如果两个摘要相同,那么就能证明报文没有被篡改
数字证书
数字证书相当于网络上的身份证,用于身份识别,由权威的数字证书认证机构(CA)负责颁发和管理。数字证书的格式普遍遵循X.509国际标准,证书的内容包括有效期、颁发机构、颁发机构的签名、证书所有者的名称、证书所有者的公钥、版本号和唯一序列号等信息。客户端会预先植入一个受信任的颁发机构的列表,如果收到的证书来自于陌生的机构,那么会弹出一个安全警报对话框。一般数字证书都会被安装在服务器处,当客户端发起安全请求时,服务器就会返回数字证书。客户端从受信机构列表中找到相应的公钥,解开数字证书。然后验证数字证书中的信息,如果验证通过,就说明请求来自意料之中的服务器;如果不通过,就说明证书被冒用,来源可疑,客户端立刻发出警告。
安全通信机制
客户端和服务器端通过好几个步骤建立起安全连接,然后开始通信。步骤大致有7个:
客户端发送Client Hello报文开始SSL通信,报文中还包括协议版本号、加密算法等信息
服务器发送Server Hello报文作为应答,在报文中也会包括协议版本号、加密算法等信息
服务器发送数字证书,数字证书中包括服务器的公钥
客户端解开并验证数字证书,验证通过后,生成一个随机密码串(Premaster Secret),再用收到的服务器公钥加密,发送给服务器
客户端再发送Change Cipher Spec报文,提示服务器在此条报文之后,采用刚刚生成的随机密码串进行数据加密
服务器也发送Change Cipher Spec报文
SSL连接建立完成,接下来就可以开始传输数据了。
 微信
微信 支付宝
支付宝
