
图结构
图结构
什么是图存储结构
存储具有”多对多”逻辑关系数据的结构——图存储结构。
与 链表 不同,图中存储的各个数据元素被称为顶点(而不是结点)。
注意:图存储结构中,习惯上用 Vi 表示图中的顶点,且所有顶点构成的集合通常用 V 表示,顶点的集合为 V={V1,V2,V3,V4}。
图存储结构可细分两种表现类型,分别为无向图和有向图。
图的基本常识
弧头和弧尾
有向图中,无箭头一端的顶点通常被称为”初始点”或”弧尾”,箭头直线的顶点被称为”终端点”或”弧头”。
入度和出度
对于有向图中的一个顶点 V 来说,箭头指向 V 的弧的数量为 V 的入度(InDegree,记为 ID(V));箭头远离 V 的弧的数量为 V 的出度(OutDegree,记为 OD(V))。
(V1,V2) 和 <V1,V2> 的区别
无向图中描述两顶点(V1 和 V2)之间的关系可以用 (V1,V2) 来表示,而有向图中描述从 V1 到 V2 的”单向”关系用 <V1,V2> 来表示。 由于图存储结构中顶点之间的关系是用线来表示的,因此 (V1,V2)
还可以用来表示无向图中连接 V1 和 V2 的线,又称为边;同样,<V1,V2> 也可用来表示有向图中从 V1 到 V2 带方向的线,又称为弧。
集合 VR 的含义
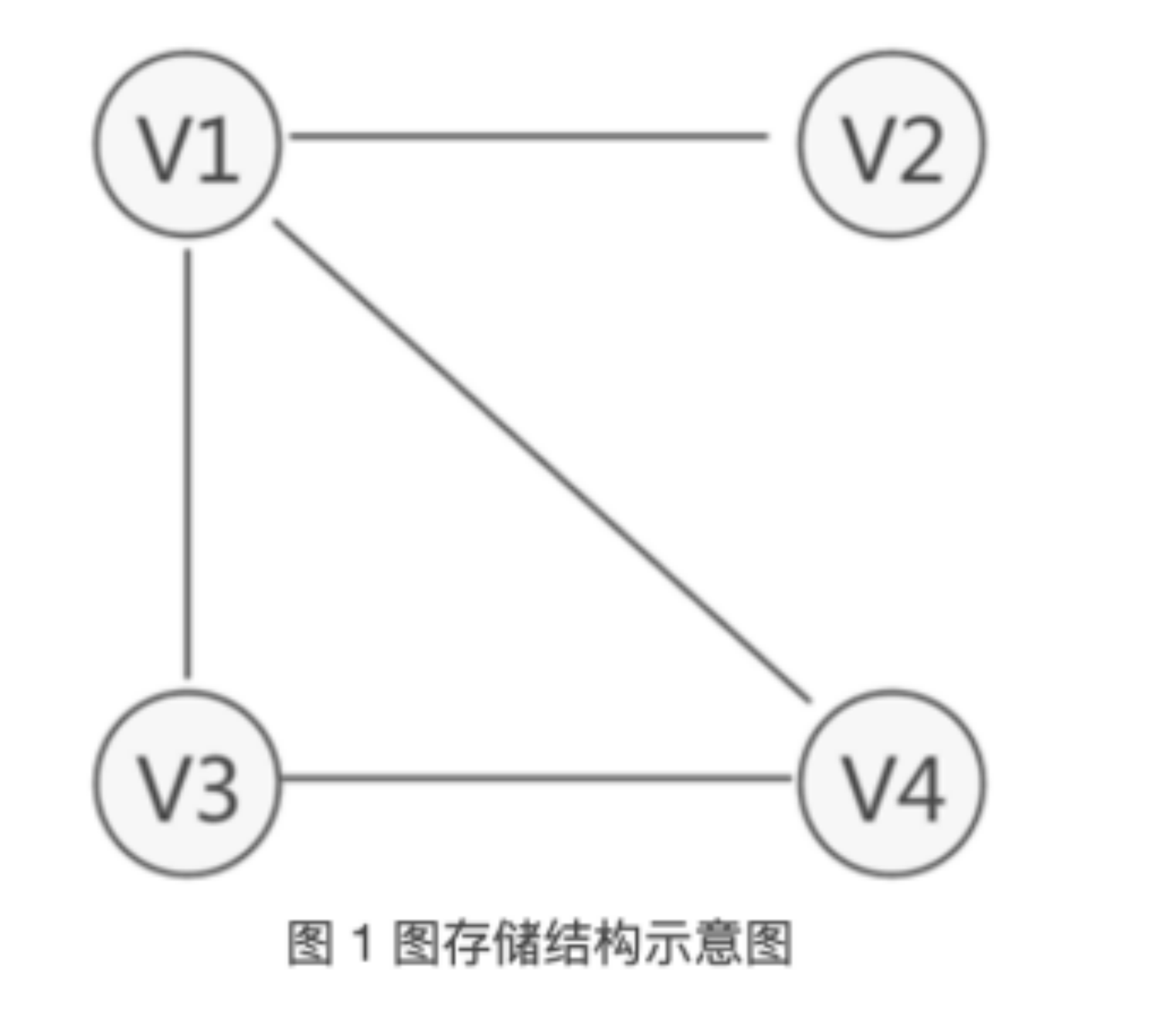
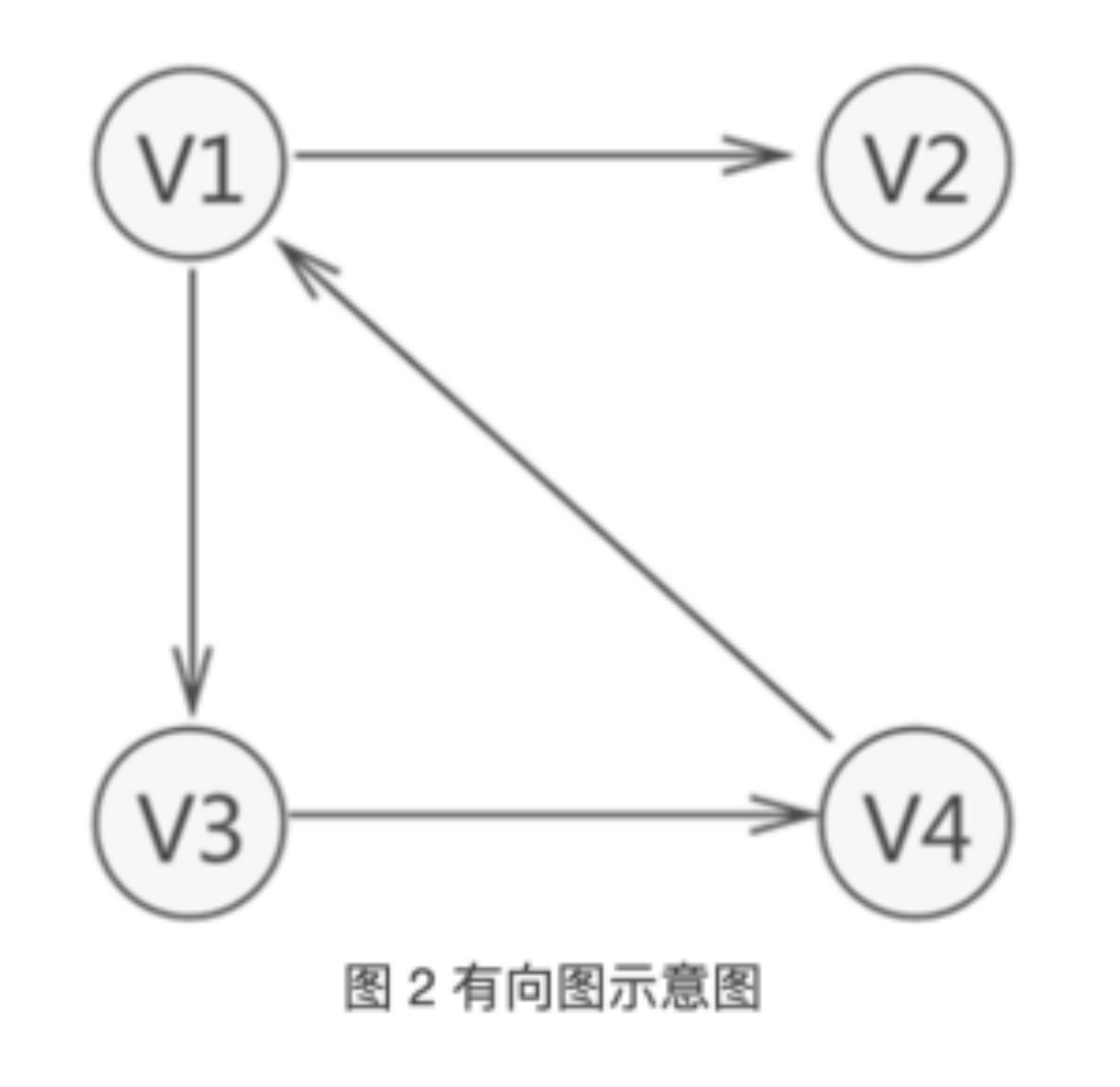
并且,图中习惯用 VR 表示图中所有顶点之间关系的集合。例如,图 1 中无向图的集合 VR={(v1,v2),(v1,v4),(v1,v3),(v3,v4)},图 2 中有向图的集合 VR={<v1,v2>,<v1,v3>,<v3,v4>
,<v4,v1>}。
路径和回路
无论是无向图还是有向图,从一个顶点到另一顶点途经的所有顶点组成的序列(包含这两个顶点),称为一条路径。如果路径中第一个顶点和最后一个顶点相同,则此路径称为”回路”(或”环”)。 并且,若路径中各顶点都不重复,此路径又被称为”简单路径”
;同样,若回路中的顶点互不重复,此回路被称为”简单回路”(或简单环)。 拿图 1 来说,从 V1 存在一条路径还可以回到 V1,此路径为 {V1,V3,V4,V1},这是一个回路(环),而且还是一个简单回路(简单环)。
注意:在有向图中,每条路径或回路都是有方向的。
权和网的含义
在某些实际场景中,图中的每条边(或弧)会赋予一个实数来表示一定的含义,这种与边(或弧)相匹配的实数被称为”权”,而带权的图通常称为网。
子图:指的是由图中一部分顶点和边构成的图,称为原图的子图。
图存储结构的分类
根据不同的特征,图又可分为完全图, 连通图 、稀疏图和稠密图:
l 完全图:若图中各个顶点都与除自身外的其他顶点有关系,这样的无向图称为完全图。同时,满足此条件的有向图则称为有向完全图。
l 稀疏图和稠密图:这两种图是相对存在的,即如果图中具有很少的边(或弧),此图就称为”稀疏图”;反之,则称此图为”稠密图”。
什么是连通图
无向图中,如果任意两个顶点之间都能够连通,则称此无向图为连通图。
若无向图不是连通图,但图中存储某个子图符合连通图的性质,则称该子图为连通分量。
注意:前面讲过,由图中部分顶点和边构成的图为该图的一个子图,但这里的子图指的是图中”最大”的连通子图(也称”极大连通子图”)。
强连通图
有向图中,若任意两个顶点 Vi 和 Vj,满足从 Vi 到 Vj 以及从 Vj 到 Vi 都连通,也就是都含有至少一条通路,则称此有向图为强连通图。
若有向图本身不是强连通图,但其包含的最大连通子图具有强连通图的性质,则称该子图为强连通分量。
总结
连通图是在无向图的基础上对图中顶点之间的连通做了更高的要求,而强连通图是在有向图的基础上对图中顶点的连通做了更高的要求。
什么是生成树(生成森林)
对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为生成树。
注意:连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。
连通图中的生成树必须满足以下 2 个条件:
包含连通图中所有的顶点;
任意两顶点之间有且仅有一条通路;
因此,连通图的生成树具有这样的特征,即生成树中边的数量 = 顶点数 - 1。
生成森林
生成树是对应连通图来说,而生成森林是对应非连通图来说的。
非连通图可分解为多个连通分量,而每个连通分量又各自对应多个生成树(至少是 1 棵),因此与整个非连通图相对应的,是由多棵生成树组成的生成森林。
因此,多个连通分量对应的多棵生成树就构成了整个非连通图的生成森林。
图的顺序存储结构
使用图构表示的数据元素之间虽然具有“多对多”的关系,但是同样可以采用顺序存储,也就是使用数组有效地存储图。
使用数组存储图时,需要使用两个数组,一个数组存放图中顶点本身的数据(一维数组),另外一个数组用于存储各顶点之间的关系(二维数组)。
注意:存储图中各顶点本身数据,使用一维数组就足够了;存储顶点之间的关系时,要记录每个顶点和其它所有顶点之间的关系,所以需要使用二维数组。
不同类型的图,存储的方式略有不同,根据图有无权,可以将图划分为两大类:图和网 。
注意:图,包括无向图和有向图;网,是指带权的图,包括无向网和有向网。存储方式的不同,指的是:在使用二维数组存储图中顶点之间的关系时,如果顶点之间存在边或弧,在相应位置用 1 表示,反之用 0
表示;如果使用二维数组存储网中顶点之间的关系,顶点之间如果有边或者弧的存在,在数组的相应位置存储其权值;反之用 0 表示。
具体实现
省略。
图的邻接表存储法
通常,图更多的是采用链表存储,具体的存储方法有 3 种,分别是邻接表、邻接多重表和十字链表。
在图中,如果两个点相互连通,即通过其中一个顶点,可直接找到另一个顶点,则称它们互为邻接点。
注意:邻接指的是图中顶点之间有边或者弧的存在。
邻接表存储图的实现方式是,给图中的各个顶点独自建立一个链表,用结点存储该顶点,用链表中其他结点存储各自的邻接点。
与此同时,为了便于管理这些链表,通常会将所有链表的头结点存储到数组中(也可以用链表存储)。也正因为各个链表的头结点存储的是各个顶点,因此各链表在存储邻接点数据时,仅需存储该邻接顶点位于数组中的位置下标即可。
邻接表计算顶点的出度和入度
使用邻接表计算无向图中顶点的入度和出度会非常简单,只需从数组中找到该顶点然后统计此链表中结点的数量即可。
而使用邻接表存储有向图时,通常各个顶点的链表中存储的都是以该顶点为弧尾的邻接点,因此通过统计各顶点链表中的结点数量,只能计算出该顶点的出度,而无法计算该顶点的入度。
对于利用邻接表求某顶点的入度,有两种方式:
遍历整个邻接表中的结点,统计数据域与该顶点所在数组位置下标相同的结点数量,即为该顶点的入度;
建立一个逆邻接表,该表中的各顶点链表专门用于存储以此顶点为弧头的所有顶点在数组中的位置下标。
图的十字链表存储法
与邻接表不同,十字链表法仅适用于存储有向图和有向网。不仅如此,十字链表法还改善了邻接表计算图中顶点入度的问题。
十字链表存储有向图(网)的方式与邻接表有一些相同,都以图(网)中各顶点为首元结点建立多条链表,同时为了便于管理,还将所有链表的首元结点存储到同一数组(或链表)中。
首元结点中有一个数据域和两个指针域(分别用 firstin 和 firstout 表示):
firstin 指针用于连接以当前顶点为弧头的其他顶点构成的链表;
firstout 指针用于连接以当前顶点为弧尾的其他顶点构成的链表;
data 用于存储该顶点中的数据;
注意:由此可以看出,十字链表实质上就是为每个顶点建立两个链表,分别存储以该顶点为弧头的所有顶点和以该顶点为弧尾的所有顶点。
十字链表中普通结点的存储分为 5 部分内容,它们各自的作用是:
tailvex 用于存储以首元结点为弧尾的顶点位于数组中的位置下标;
headvex 用于存储以首元结点为弧头的顶点位于数组中的位置下标;
hlink 指针:用于链接下一个存储以首元结点为弧头的顶点的结点;
tlink 指针:用于链接下一个存储以首元结点为弧尾的顶点的结点;
info 指针:用于存储与该顶点相关的信息,例如两顶点之间的权值;
具体实现
省略。
图的邻接多重表存储法
注意,邻接多重表仅适用于存储无向图或无向网。
邻接多重表存储无向图的方式,可看作是邻接表和十字链表的结合。同邻接表和十字链表存储图的方法相同,都是独自为图中各顶点建立一张链表,存储各顶点的结点作为各链表的首元结点,同时为了便于管理将各个首元结点存储到一个数组中。
各区域及其功能为:
l data:存储此顶点的数据;
l firstedge:指针域,用于指向同该顶点有直接关联的存储其他顶点的结点。
邻接多重表采用与邻接表相同的首元结点结构。但各链表中其他结点的结构与十字链表中相同:
l mark:标志域,用于标记此结点是否被操作过,例如在对图中顶点做遍历操作时,为了防止多次操作同一结点,mark 域为 0 表示还未被遍历;mark 为 1 表示该结点已被遍历;
l ivex 和 jvex:数据域,分别存储图中各边两端的顶点所在数组中的位置下标;
l ilink:指针域,指向下一个存储与 ivex 有直接关联顶点的结点;
l jlink:指针域,指向下一个存储与 jvex 有直接关联顶点的结点;
l info:指针域,用于存储与该顶点有关的其他信息,比如无向网中各边的权;
深度优先搜索(DFS)和广度优先搜索(BFS)
本节介绍如何对存储的图中的顶点进行遍历。常用的遍历方式有两种:深度优先搜索和广度优先搜索。
DFS
所谓深度优先搜索,是从图中的一个顶点出发,每次遍历当前访问顶点的邻接点,一直到访问的顶点没有未被访问过的邻接点为止。然后采用依次回退的方式,查看来的路上每一个顶点是否有其它未被访问的邻接点。访问完成后,判断图中的顶点是否已经全部遍历完成,如果没有,以未访问的顶点为起始点,重复上述过程。
注意:深度优先搜索是一个不断回溯的过程。
BFS
广度优先搜索类似于树的层次遍历。从图中的某一顶点出发,遍历每一个顶点时,依次遍历其所有的邻接点,然后再从这些邻接点出发,同样依次访问它们的邻接点。按照此过程,直到图中所有被访问过的顶点的邻接点都被访问到。
最后还需要做的操作就是查看图中是否存在尚未被访问的顶点,若有,则以该顶点为起始点,重复上述遍历的过程。
具体实现
省略。
总结
本节介绍了两种遍历图的方式:深度优先搜索算法和广度优先搜索算法。深度优先搜索算法的实现运用的主要是回溯法,类似于树的先序遍历算法。广度优先搜索算法借助队列的先进先出的特点,类似于树的层次遍历。
深度优先生成树(生成森林)和广度优先生成树(生成森林)
由深度优先搜索得到的树为深度优先生成树。同理, 广度优先搜索生成的树为广度优先生成树。
非连通图的生成森林
非连通图在进行遍历时,实则是对非连通图中每个连通分量分别进行遍历,在遍历过程经过的每个顶点和边,就构成了每个连通分量的生成树。 非连通图中,多个连通分量构成的多个生成树为非连通图的生成森林。
深度优先生成森林
注意:非连通图在遍历生成森林时,可以采用孩子兄弟表示法将森林转化为一整棵二叉树进行存储。
具体实现
省略。
广度优先生成森林
非连通图采用广度优先搜索算法进行遍历时,经过的顶点以及边的集合为该图的广度优先生成森林。
具体实现
省略。
重连通图及重连通分量
在无向图中,如果任意两个顶点之间含有不止一条通路,这个图就被称为重连通图。在重连通图中,在删除某个顶点及该顶点相关的边后,图中各顶点之间的连通性也不会被破坏。
在一个无向图中,如果删除某个顶点及其相关联的边后,原来的图被分割为两个及以上的连通分量,则称该顶点为无向图中的一个关结点(或者“割点”)。
注意:重连通图其实就是没有关结点的连通图。
在重连通图中,只删除一个顶点及其相关联的边,肯定不会破坏其连通性。如果一味地做删除顶点的操作,直到删除 K 个顶点及其关联的边后,图的连通性才遭到破坏,则称此重连通图的连通度为 K。
关键路径
AOE 网
AOE 网是在 AOV 网的基础上,其中每一个边都具有各自的权值,是一个有向无环网。其中权值表示活动持续的时间。
解决这个问题的关键在于从 AOE 网中找到一条从起始点到结束点长度最长的路径,这样就能保证所有的活动在结束之前都能完成。
起始点是入度为 0 的点,称为“源点”;结束点是出度为 0 的点,称为“汇点”。这条最长的路径,被称为“关键路径”。
关键路径
为了求出一个给定 AOE 网的关键路径,需要知道以下 4 个统计数据:
l 对于 AOE 网中的顶点有两个时间:最早发生时间(用 Ve(j) 表示)和最晚发生时间(用 Vl(j) 表示);
l 对于边来说,也有两个时间:最早开始时间(用 e(i) 表示)和最晚开始时间( l(i) 表示)。
Ve(j):对于 AOE 网中的任意一个顶点来说,从源点到该点的最长路径代表着该顶点的最早 发生时间,通常用 Ve(j) 表示。
Vl(j):表示在不推迟整个工期的前提下,事件 Vk 允许的最晚发生时间。
e(i):表示活动 ai 的最早开始时间,如果活动 ai 是由弧 <Vk,Vj> 表示的,那么活动 ai 的 最早开始的时间就等于时间 Vk 的最早发生时间,也就是说:e[i] = ve[k]。
l(i):表示活动 ai 的最晚开始时间,如果活动 ai 是由弧 <Vk,Vj> 表示,ai 的最晚开始时间 的设定要保证 Vj 的最晚发生时间不拖后。所以,l[i]=Vl[j]-len<Vk,Vj>。
在得知以上四种统计数据后,就可以直接求得 AOE 网中关键路径上的所有的关键活动,方法是:对于所有的边来说,如果它的最早开始时间等于最晚开始时间,称这条边所代表的活动为关键活动。由关键活动构成的路径为关键路径。
具体实现
省略。
 微信
微信 支付宝
支付宝
