
MySQL 索引
1. 跟索引相关的一些算法
B+Tree 是借鉴了二分查找法、二叉查找树、平衡二叉树、B-Tree 的一些思想构建的。我们通过了解这些算法,来一层一层拨开 B+Tree 的面纱。
1.1 二分查找法
二分查找法的查找过程是:将记录按顺序排列,查找时先以有序列的中点位置为比较对象,如果要找的元素值小于该中点元素,则将查询范围缩小为左半部分;如果要找的元素值大于该中点元素,则将查询范围缩小为右半部分。以此类推,直到查到需要的值。
1.2 二叉查找树
二叉查找树中,左子树所有节点的值都小于父节点的值,右子树所有节点的值都大于父节点键值,并且每个节点最多只有两棵子树。
1.3 平衡二叉(查找)树
满足二叉树的定义,并且满足任何节点的两棵子树的高度差最大为 1。
1.4 B-Tree(平衡多路查找树)
B-Tree 可以理解为一个节点可以拥有 2 个子节点的多路查找树。
B-Tree 中同一键值不会出现多次,要么在叶子节点,要么在内节点上。
比如用 1、2、3、5、6、7、9 这些数字构建一个 B-Tree 结构,其图形如下:
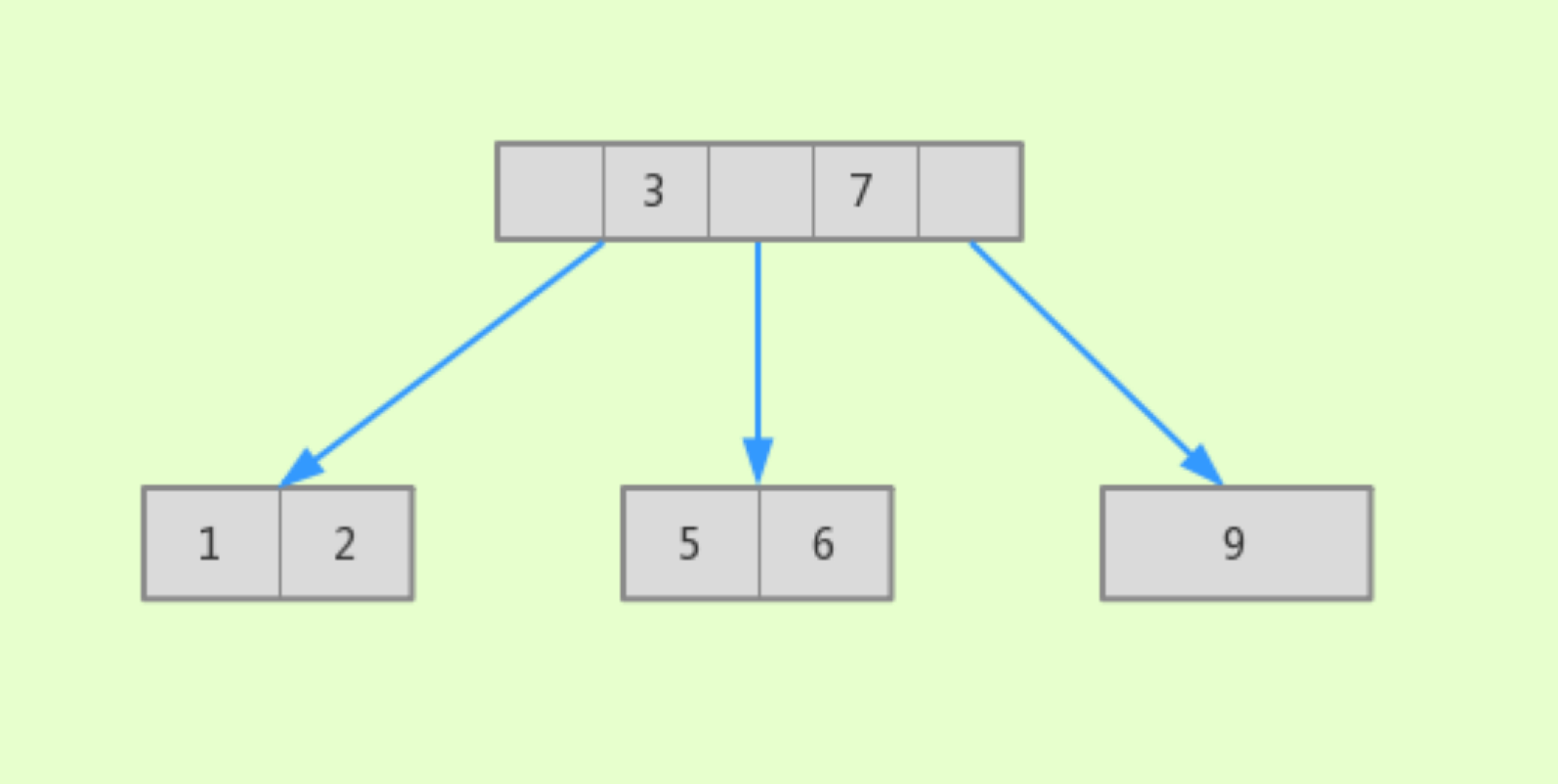
与平衡二叉树相比,B-Tree 利用多个分支节点,减少获取记录时经历的节点数。
B-Tree 也是有缺点的,因为每个节点都包含 key 值和 data 值,因此若 data 比较大时,每一页存储的 key 会比较少;当数据比较多时,同样会:要经历多层节点才能查询在叶子节点的数据的问题。这时,B+Tree 站出来了。
1.5 B+Tree
B+Tree 是 B-Tree 的变体,定义基本与 B-Tree 一致,与 B-Tree 的不同如下:
- 所有叶子节点中包含了全部关键字的信息
- 各叶子节点使用指针进行连接
- 非叶子节点上只存储
key的信息,这样相对于B-Tree,可以增加每一页中key的数量
在 B+Tree中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上。B+Tree中的 B 不是代表二叉 (binary) 而是代表平衡(balance),B+Tree并不是一个二叉树。
还是根据前面提到的这组数字(1、2、3、5、6、7、9)举例,它的结构如下:
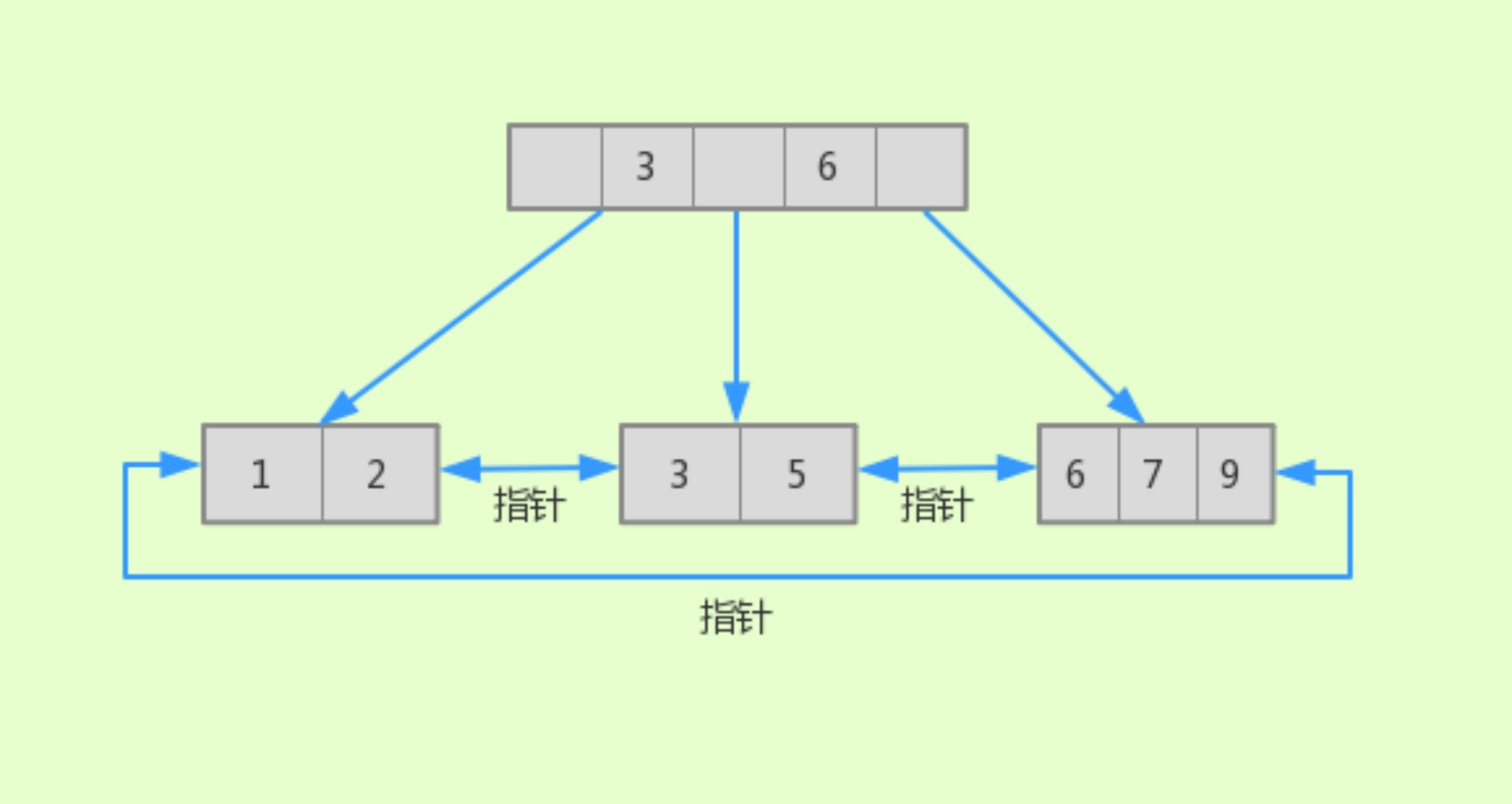
与 B-Tree 的结构的最大区别是:
它的键一定出现在叶子节点上,同时也有可能在非叶子节点上重复出现,而 B-Tree 中同一键值不会出现多次。
2.B+Tree 索引
B+Tree 索引是基于 B+Tree 发展而来的。在数据库中,B+Tree 的高度一般在 24 层,所以查找某一行数据最多需要 24 次 IO,而没有索引时,需要逐行扫描,明显效率低很多,这就是为什么添加索引能提高查询速度。
B+Tree 索引并不能找到一个给定键值的具体行,B+Tree 索引能找到的是被查找数据行所在的页,然后数据库将该页读入到缓冲池(buffer pool)中,在内存中通过二分查找法查找,得到需要的数据。
InnoDB 中 B+Tree 索引分为聚簇索引和辅助索引,我们来了解这两种索引的特点。
2.1 聚簇索引
InnoDB 的数据是按照主键顺序存放的,而聚簇索引就是按照每张表的主键构造的一棵 B+Tree,它的叶子节点存放了整行的数据。
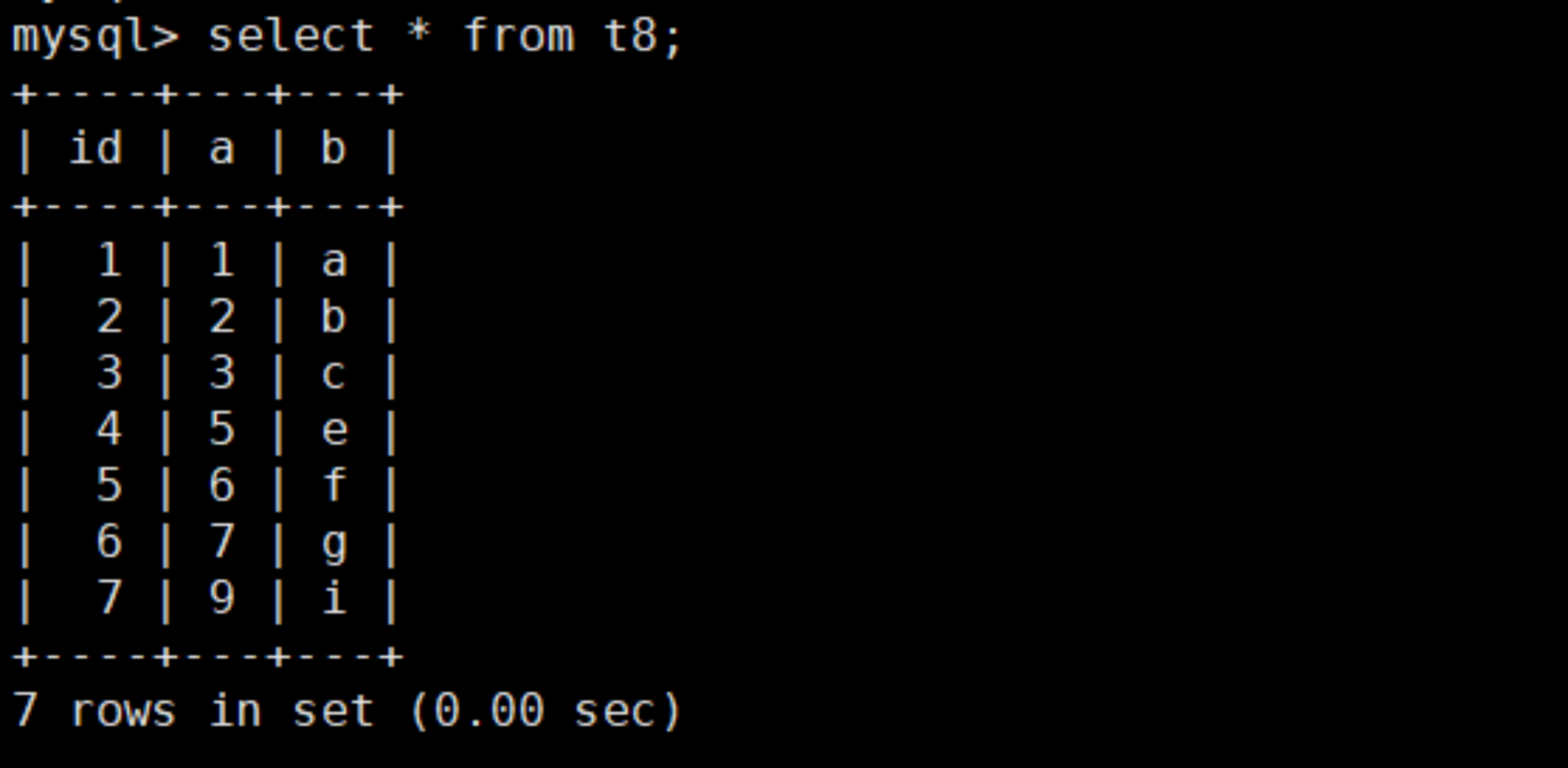
创建测试表 t8,查询结果如下:
t8 的聚簇索引的大致结构如下:
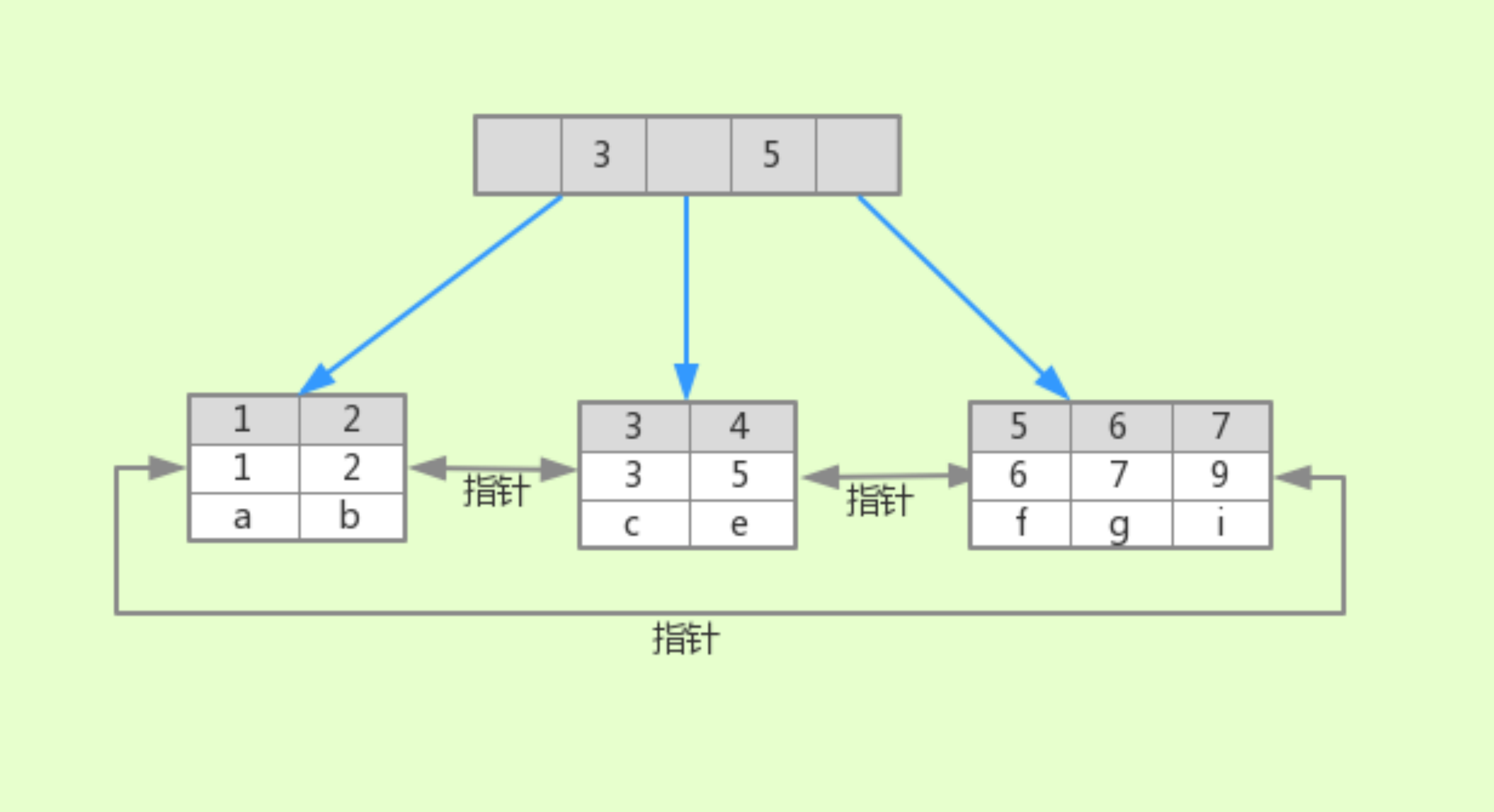
两点关键信息:
- 根据主键值创建了
B+Tree结构 - 每个叶子节点包含了整行数据
2.2 辅助索引
辅助索引的叶子节点不会存放整行数据,而是存放了键值和主键 ID。
当通过辅助索引来寻找数据时,InnoDB 存储引擎会遍历辅助索引树查找到对应记录的主键,然后通过主键索引找到对应的行数据。
我们继续拿 t8 分析,它的辅助索引 idx_a 结构如下:
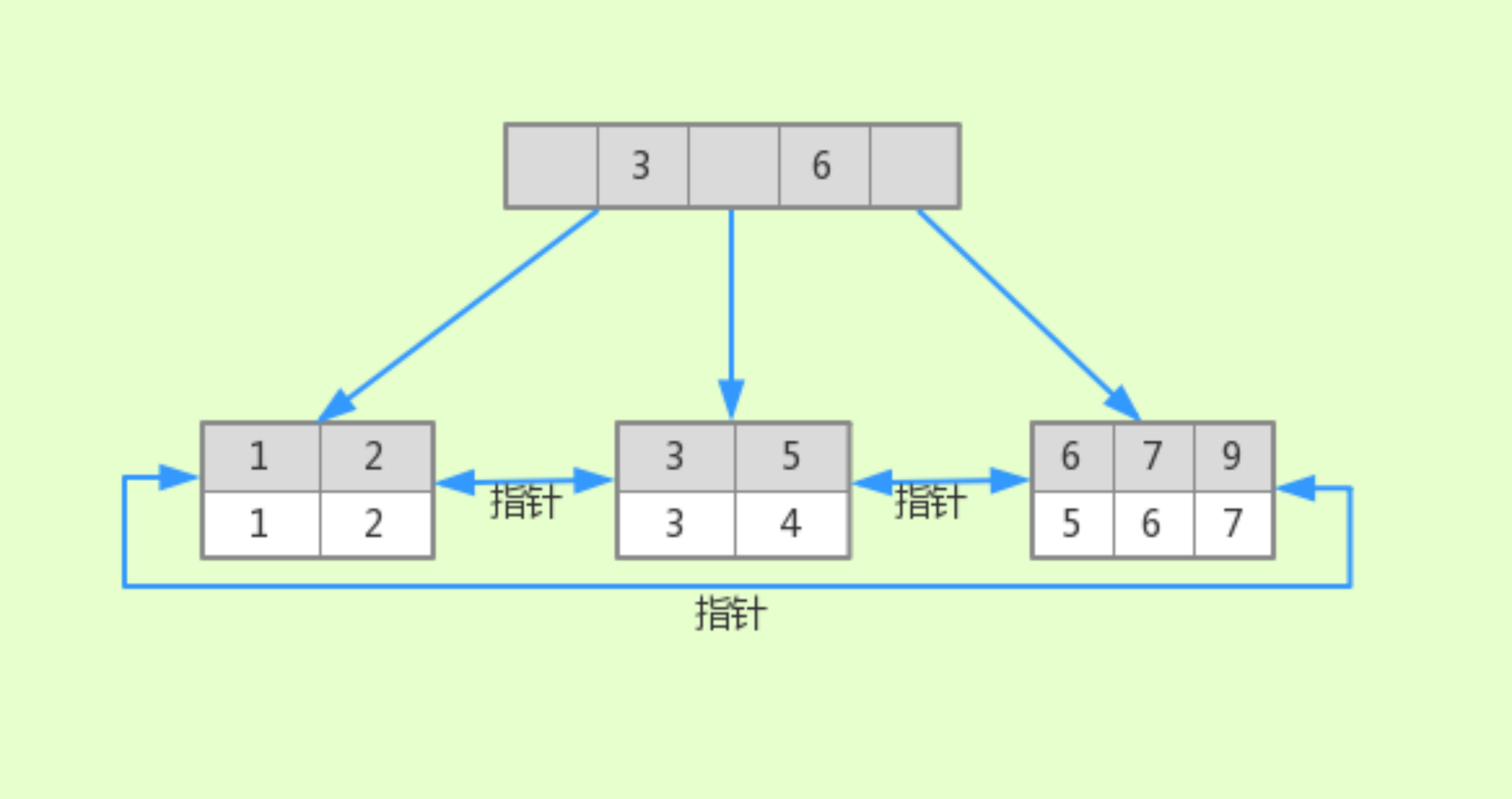
两点关键信息:
- 根据 a 字段的值创建了
B+Tree结构 - 每个叶子节点保存的是 a 字段自己的键值和主键 ID
3. 哪些情况需要添加索引?
目前常见的添加索引的场景有:数据检索时在条件字段添加索引、聚合函数对聚合字段添加索引、对排序字段添加索引、为了防止回表添加索引、关联查询在关联字段添加索引等。
4. 普通索引和唯一索引有哪些区别?
本节在讲普通索引和唯一索引的区别时,首先提到了 Insert Buffer,其目的是将多次插入合并。InnoDB 从 1.0.x 版本开始,开始支持增删改操作,统一称为 Change Buffer。
普通索引和唯一索引的区别:
- 有普通索引的字段可以写入重复的值,而有唯一索引的字段不可以写入重复的值
- 数据修改时,普通索引优于唯一索引,因为普通索引可以用
Change Buffer,并且RR隔离级别下,出现死锁的概率比唯一索引低。 - 查询数据时,两者性能差别不大。
5. 联合索引有哪些讲究?
使用联合索引的情况:
- 可以完整用到联合索引的情况
- 只能使用部分联合索引的情况
- 可以用到覆盖索引的情况
- 不能使用联合索引的情况
可以结合自己的需求考虑是否通过创建联合索引代替单个字段的索引,在使用时也需要清楚联合索引的使用技巧,避免出现走不了索引的情况。
6. 为什么 MySQL 会选错索引?
本节介绍了 show index 的各个字段的含义,并重点说明了 Cardinality 的取值原理。
通过学习了 Cardinality 的取值原理,我们知道了它的值只是一个估值,因此当我们遇到它的值与实际值相差很大时,可以考虑使用:analyze table xxx; 重新获取统计信息。
另外举例说明了单次选取的数据量过大也有可能导致优化器选错索引,这种时候,可以尝试使用 force index 让 sql 强制走某个索引。
 微信
微信 支付宝
支付宝
