
MySQL 事务
1.数据库突然断电会丢数据吗?
1.1 什么是事务?
根据《高性能 MySQL》第 3 版 1.3 事务一节中定义:
事务就是一组原子性的 SQL 查询,或者说一个独立的工作单元。如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组查询。如果其中有任何一条语句因为崩溃或其他原因无法执行,那么所有的语句都不会执行。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
一个良好的事务处理系统,必须具备 ACID 特性:
atomicity(原子性) :要么全部执行,要么全部都不执行。原子性是由undo log来保证的,因为undo log记录着数据修改前的信息。consistency(一致性):在事务开始和完成时,数据都必须保持一致状态。一致性是事务的目的,一致性由应用程序来保证。isolation(隔离性):事务处理过程中的中间状态对外部是不可见的。隔离性由数据库提供隔离级别供我们选择,分别有read uncommitted, read committed, repeatable read, serializable。durability(持久性):事务完成之后,它对于数据的修改是永久性的。持久性由redo log来保证。
Redo log
Redo log 称为重做日志,用于记录事务操作变化,记录的是数据被修改之后的值。
Redo log 由两部分组成:
- 内存中的重做日志缓冲(
redo log buffer) - 重做日志文件(
redo log file)
每次数据更新会先更新 redo log buffer,然后根据innodb_flush_log_at_trx_commit 来控制 redo log buffer 更新到 redo log file 的时机。innodb_flush_log_at_trx_commit 有三个值可选:
- 0:事务提交时,每秒触发一次
redo log buffer写磁盘操作,并调用操作系统fsync刷新 IO 缓存。 - 1:事务提交时,
InnoDB立即将缓存中的redo日志写到日志文件中,并调用操作系统fsync刷新 IO 缓存; - 2:事务提交时,
InnoDB立即将缓存中的redo日志写到日志文件中,但不是马上调用fsync刷新 IO 缓存,而是每秒只做一次刷新 IO 缓存操作。
innodb_flush_log_at_trx_commit 参数的默认值是 1,也就是每个事务提交的时候都会将 redo log buffer 中的写更新记录到日志文件,而且会刷新磁盘缓存,这完全满足事务持久化的要求,是最安全的,但是这样会有比较大的性能损失。将参数设置为 0 时,如果数据库崩溃,最后 1 秒钟的 redo log 可能会由于未及时写入磁盘文件而丢失,这种方式尽管效率最高,但是最不安全。将参数设置为 2 时,如果数据库崩溃,由于已经执行了重做日志写入磁盘的操作,只是没有做磁盘 IO 刷新操作,因此,只要不发生操作系统崩溃,数据就不会丢失,这种方式是对性能和安全的一种折中处理。
1.2 Binlog
二进制日志(binlog)记录了所有的 DDL(数据定义语句)和 DML(数据操纵语句),但是不包括 select 和 show 这类操作。Binlog 有以下几个作用:
- 恢复:数据恢复时可以使用二进制日志
- 复制:通过传输二进制日志到从库,然后进行恢复,以实现主从同步
- 审计:可以通过二进制日志进行审计数据的变更操作
可以通过参数 sync_binlog 来控制累积多少个事务后才将二进制日志 fsync 到磁盘。
sync_binlog=0,表示每次提交事务都只write,不fsyncsync_binlog=1,表示每次提交事务都会执行fsyncsync_binlog=N(N>1),表示每次提交事务都write,累积 N 个事务后才fsync
比如要加快写入数据的速度或者机器磁盘 IO 瓶颈时,可以将 sync_binlog 设置成大于 1 的值,但是如果设置为 N(N>1)时,如果数据库崩溃,可能会丢失最近 N 个事务的 binlog。
怎样确保数据库突然断电时不丢数据?
通过上面的讲解,只要 innodb_flush_log_at_trx_commit 和 sync_binlog 都为 1(通常称为:双一),就能确保 MySQL 机器断电重启后,数据不丢失。因此建议在比较重要的库,比如涉及到钱的库,设置为双一,而你的测试环境或者正式业务不那么重要的库(比如日志库)可以将 innodb_flush_log_at_trx_commit 设置为 0,sync_binlog 设置成大于 100 的数值,提高更新效率。
2. MVCC 如何实现的?
MVCC(Multi-Version Concurrency Control,多版本并发控制)。
2.1 隐藏列
对于 InnoDB,每行记录除了我们创建的字段外,其实还包含 3 个隐藏的列:
ROW ID:隐藏的自增 ID,如果表没有主键,InnoDB会自动以ROW ID产生一个聚簇索引树。- 事务 ID:记录最后一次修改该记录的事务 ID。
- 回滚指针:指向这条记录的上一个版本。
2.2 Undo log
Undo log 就发挥了作用。Undo log 是逻辑日志,将数据库逻辑地恢复到原来的样子,所有修改都被逻辑的取消了。
- 也就是如果是
insert操作,其对应的回滚操作就是delete; - 如果是
delete,则对应的回滚操作是insert; - 如果是
update,则对应的回滚操作是一个反向的update操作。
Undo log 的作用除了回滚操作,Undo log 的另一个作用是 MVCC,InnoDB 存储引擎中 MVCC 的实现是通过 Read View + Undo log 来完成的。当用户读取一行记录时,若该记录已经被其它事务占用,当前事务可以通过 Undo log 读取之前的行版本信息,因为没有事务需要对历史的数据进行修改操作,所以也不需要加锁,以此来实现非锁定读取。
2.3 Read View
Read View 是指事务进行快照读操作的那一刻,产生数据库系统当前活跃事务列表的一个快照。
Read View 中大致包含以下内容:
trx_ids:数据库系统当前活跃事务 ID 集合;low_limit_id:活跃事务中最大的事务 ID +1;up_limit_id:活跃事务中最小的事务 ID;creator_trx_id:创建这个Read View的事务 ID。
比如某个事务,创建了 Read View,那么它的 creator_trx_id 就为这个事务的 ID,假如需要访问某一行,假设这一行记录的隐藏事务 ID 为 t_id,那么可能出现的情况如下:
- 如果
t_id < up_limt_id,说明这行记录在这些活跃的事务创建之前就已经提交了,那么这一行记录对该事务是可见的。 - 如果
t_id >= low_limt_id,说明这行记录在这些活跃的事务开始之后创建的,那么这一行记录对该事物是不可见的。 - 如果
up_limit_id <= t_id < low_limit_id,说明这行记录可能是在这些活跃的事务中创建的,如果t_id也同时在trx_ids中,则说明t_id还未提交,那么这一行记录对该事物是不可见的;如果t_id不在trx_ids中,则说明事务t_id已经提交了,那么这一行记录对该事物是可见的。
对于不可见的记录,都是通过查询 Undo log 来查询老的记录。
了解了上面的原理,我们知道了,Read View 规则帮我们判断当前版本的数据是否可见。下面,我们分析下当查询一条记录时,大致的步骤:
- 获取事务本身的事务 ID;
- 获取
Read View; - 查询得到的数据,然后与
Read View中的事务版本号进行比较; - 如果能查询,则直接查询对应的记录;如果不能直接查询,则通过
Undo Log获取历史快照; - 最终返回结果。
另外需要补充的一点就是,在 RR 和 RC 隔离级别下,获取 Read View 的时机也是不一样的:
- 在可重复读隔离级别(
RR)下,同一个事务中,查询语句只是在第一个读请求发起时获取Read View,而后面相同的查询语句都会使用这个Read View。 - 在读已提交隔离级别(
RC)下,同一个事务中,同样的查询语句在每次读请求发起时都会获得Read View。
2.4 什么是 MVCC?
在 session1 更新了 a=1 这行记录,但还没提交的情况下,在 session2 中,满足 a=1 这条记录,b 的值还是原始值 1,而不是 session 1 更新之后的 666,那么在数据库层面,这是怎么实现的呢?
其实 InnoDB 就是通过 MVCC 和 Undo log 来实现的。
什么是 MVCC
MVCC, 即多版本并发控制。MVCC 的实现,是通过保存数据在某个时间点的快照来实现的,也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。也就是上面实验第 6 步中,为什么 session2 查询的结果还是 session1 修改之前的记录。
MVCC 的实现原理
我们拿上面的例子,对应解释下 MVCC 的实现原理,如下图:
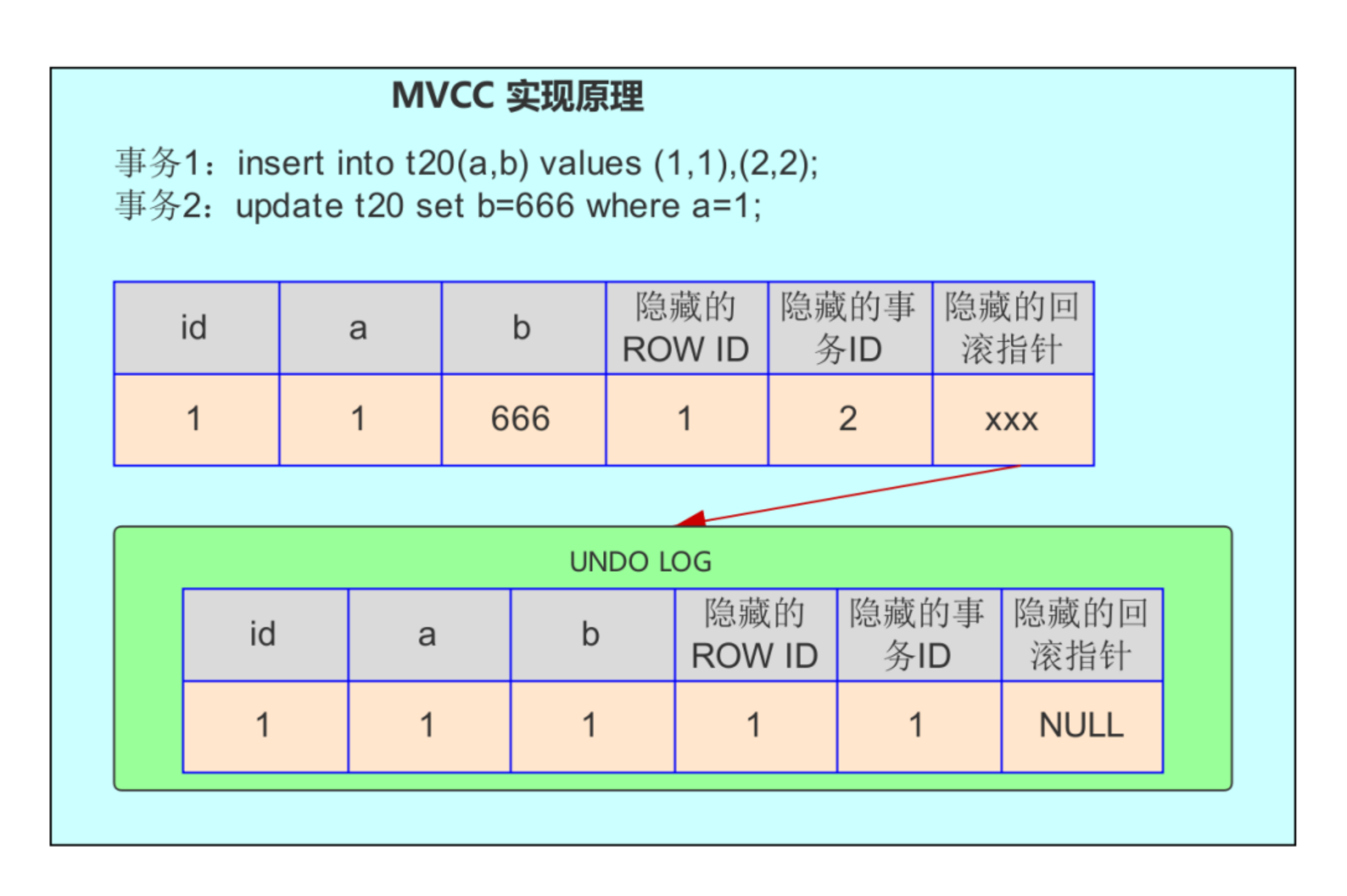
如图,首先 insert 语句向表 t20 中插入了一条数据,a 字段为 1,b 字段为 1,ROW ID 也为 1,事务 ID 假设为 1,回滚指针假设为 null。当执行 update t20 set b=666 where a=1 时,大致步骤如下:
- 数据库会先对满足 a=1 的行加排他锁;
- 然后将原记录复制到 undo 表空间中;
- 修改 b 字段的值为 666,修改事务 ID 为 2;
- 并通过隐藏的回滚指针指向
Undo log中的历史记录; - 事务提交,释放前面对满足 a=1 的行所加的排他锁。
在前面实验的第 6 步中,session2 查询的结果是 session1 修改之前的记录,也就是那个点的 Read View,根据上面将的 Read View 原理,被查询行的隐藏事务 ID 就在当前活跃事务 ID 集合中。因此,这一行记录对该事物(session2 中的事务)是不可见的,可以知道 session2 查询的 a=1 这行记录实际就是来自 Undo log 中。我们看到的现象就是同一条记录在系统中存在了多个版本,这就是 MySQL 的多版本并发控制(MVCC)。需要注意的是,MVCC 只在 RC 和 RR 两个隔离级别下工作。因此在上面的实验中,改成 RR 隔离级别,第 6 步中,得到的结果还是 session1 修改之前的记录.
2.5 MVCC 的优势
MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的 I 特性。
3. 不同事物隔离级别有哪些区别?
3.1 通过基本定义认识事务隔离级别
MySQL 有四种隔离级别,这四种隔离级别的定义如下:
Read Uncommitted(读未提交,简称:RU): 在该隔离级别,所有事务都可以看到其它未提交的事务的执行结果。可能会出现脏读。Read Committed(读已提交,简称:RC):一个事务只能看见已经提交事务所做的改变。因为同一事务的其它实例在该实例处理期间可能会有新的 commit,所以可能出现幻读。Repeatable Read(可重复读,简称:RR):这是 MySQL 的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。消除了脏读、不可重复读,默认也不会出现幻读。Serializable(串行化):这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。
3.2 通过生活中的例子认识事务隔离级别
Read uncommitted 的例子
拿零售业务场景来讲,在事务隔离级别 RU 下:比如顾客 A 在超市买单时,当收银员扫完顾客 A 的支付码后,因为网络原因,一直等待着(也就是整个支付过程的事务还没结束);这时收银员去后台数据查询,看到 A 的钱已经进入超市账户了,然后让顾客 A 离开。过了一会,整个支付过程回滚了,才发现 A 实际是支付失败。这样超市岂不是很亏。这就是 RU 隔离级别可能导致脏读的情况。
Read Committed 的例子
在 RC 隔离级别下:比如顾客 A 在超市购买了 90 元的东西,当收银系统查询到顾客 A 还剩 100 元,足够扣款,此时 A 的老婆在家网购,花掉了 A 账户里的这 100 块,这时收银系统在扣除 A 账户 90 元这一步操作时,就会出现报错的情况。这时顾客 A 肯定郁闷,不是明明钱够么?这就是 RC 隔离级别下的幻读现象。
Repeatable Read 的例子
还是拿上面的例子,顾客 A 在超市购买了 90 元的东西,当收银系统查询到顾客 A 还剩 100 元,足够扣款,此时 A 的老婆在家网购,能查询到 A 的账户里还有 100 元,但是想要用 A 账户里的 100 块,却发现并不能使用这 100 元。这样,A 最后的扣款步骤也能正常完成,最终顺利完成了整个付款过程。这就是可重复读的现象。
Serializable 的例子
顾客 A 在超市购买了 90 元的东西,当收银系统查询到顾客 A 还剩 100 元,足够扣款,此时 A 的老婆在家网购,想查询 A 账户里还有多少钱,却发现无法查看到,必须要等到 A 整个付款完成,其老婆才能去查询余额。这就是串行导致的。
如何选择合适的事务隔离级别
对于 RU 隔离级别,会导致脏读,从性能上看,也不会比其它隔离级别好太多,因此生产环境不建议使用。
对于 RC 隔离级别,相比 RU 隔离级别,不会出现脏读;但是会出现幻读,一个事务中的两次执行同样的查询,可能得到不一样的结果。
对于 RR 隔离级别,相比 RC 隔离级别,解决了部分幻读(这个在第 17 节详细讲了,RR 隔离级别通过Next-key Lock解决了快照读情况下的幻读),但是相对于 RC,锁的范围可能更大了。
对于 Serializable 隔离级别,因为它强制事务串行执行,会在读取的每一行数据上都加锁,因此可能会导致大量的超时和锁争用的问题。生成环境很少使用。
因此总的来说,建议在 RC 和 RR 两个隔离级别中选一种,如果能接受幻读,需要并发高点,就可以配置成 RC,如果不能接受幻读的情况,就设置成 RR 隔离级别。
4. 养成好的事物习惯
4.1 不好的事物习惯
- 在循环中提交
在类似这种循环写入的情况,如果循环次数不是太多,建议在循环前开启一个事务,循环结束后统一提交。这样只写了 1 次重做日志。
- 不关注同一个事物中的语句顺序
根据两阶段锁,整个事务里面涉及的锁,需要等到事务提交时才会释放。因此我们在同一个事务中,可以把没锁或者锁范围小的语句放在事务前面执行,而锁定范围大的语句放在后面执行。
- 不关注不同事物访问资源的顺序
- 不关注事物隔离级别
- 在事物中混合使用存储引擎
4.2 总结一下好的事物习惯
- 循环写入的情况,如果循环次数不是太多,建议在循环前开启一个事务,循环结束后统一提交。
- 优化事务里的语句顺序,减少锁时间。
- 关注不同事务访问资源的顺序。
- 创建事务之前,关注事务隔离级别。
- 不在事务中混合使用存储引擎。
5. 分布式事务
5.1 认识分布式事务
分布式事务是指一个大的事务由很多小操作组成,小操作分布在不同的服务器上或者不同的应用程序上。分布式事务需要保证这些小操作要么全部成功,要么全部失败。MySQL 从 5.0.3 开始支持分布式事务。
分布式事务使用两阶段提交协议:
- 第一阶段:所有分支事务都开始准备,告诉事务管理器自己已经准备好了;
- 第二阶段:确定是
rollback还是commit,如果有一个节点不能提交,则所有节点都要回滚。
与本地事务不同点在于:分布式事务需要多一次 prepare 操作,等收到所有节点的确定信息后,再进行 commit 或者 rollback。
MySQL 中分布式事务按实现方式分为两种:MySQL 自带的分布式事务和结合中间件实现的分布式事务。
5.2 MySQL 自带的分布式事务
但是在 MySQL 5.7 之前的版本,自带的分布式事务存在以下问题:
比如某个分支事务到达 prepare 状态时,此时数据库断电,重启后,可以继续对分支事务进行提交或者回滚,但是提交的事务不会写 binlog,如果有从库,会导致主从数据不一致的情况。
如果分支事务的客户端连接异常中止,那么数据库会自动回滚当前分支未完成的事务,如果此时分支事务已经到 prepare 状态,那么这个分布式事务的其他分支可能已经成功提交,如果这个分支回滚,可能导致分布式事务的不完整,丢失部分分支事务的内容。
还有一种情况,如果分支事务在执行到 prepare 状态时,数据库出现故障,并且无法启动,需要使用全备和 binlog 来恢复数据,那么这些在 prepare 状态的分支事务因为没有记录到 binlog,所以也不能通过 binlog 进行恢复,在数据库恢复后,将丢失这部分数据。所以,MySQL 5.7 之前的版本自带的分布式事务还存在比较严重的缺陷,在有些场景下,会导致数据丢失。如果业务对数据完整性要求不高,可以考虑使用,如果对数据完整性要求比较高,需要考虑先升级到 5.7 版本。
5.3 结合中间件实现分布式事务
具体实现方式可以拿上面网上购书的例子来说:
订单业务程序处理完增加订单的操作后,将减库存操作发送到消息队列中间件中(比如:RocketMQ),订单业务程序完成提交。然后库存业务程序检查到消息队列有减对应商品库存的信息,就开始执行减库存操作。库存业务执行完减库存操作,再发送一条消息给消息队列中间件:内容是已经减掉库存。具体步骤如下:
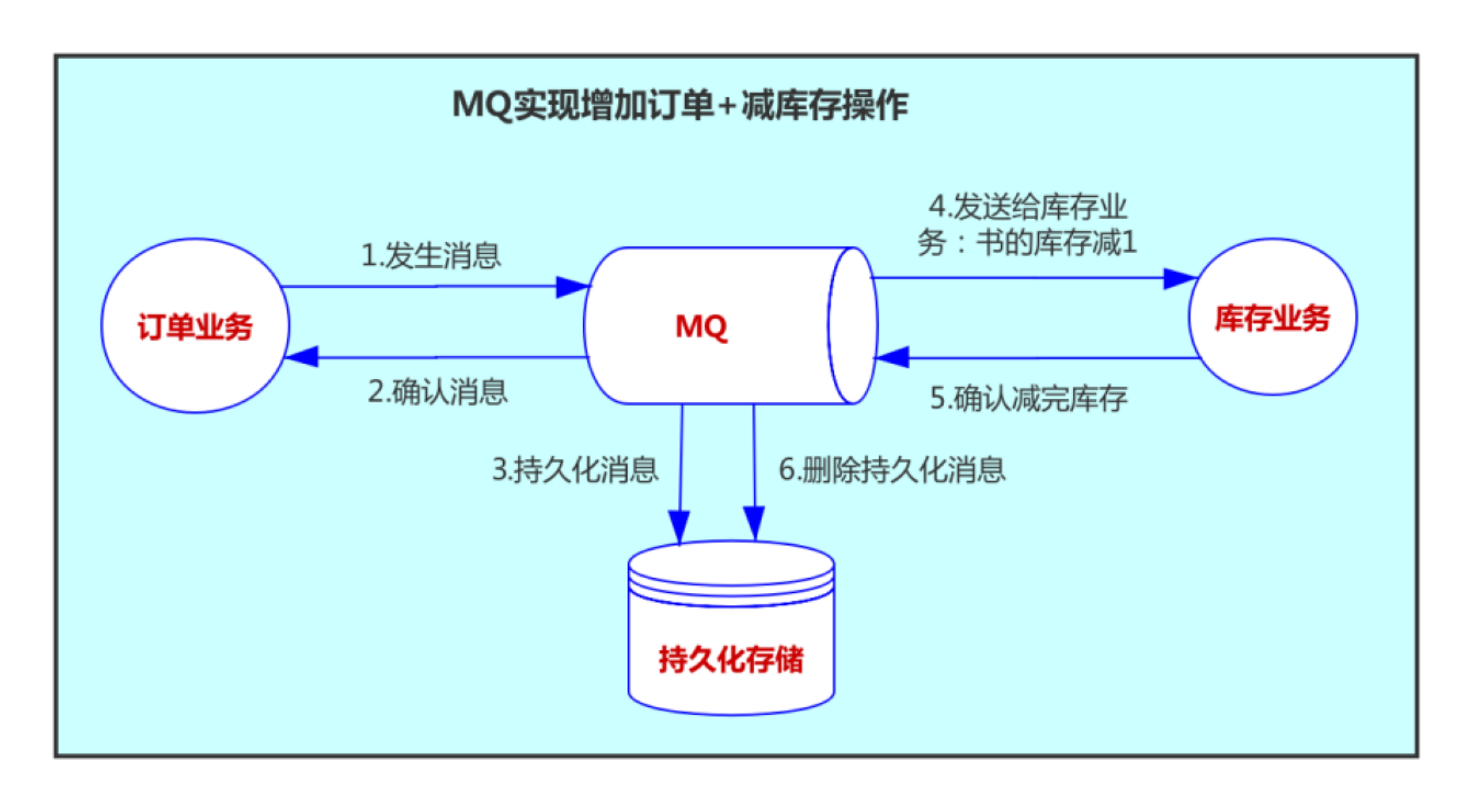
当然,为了确定最终已经完成减库存操作,还可以加一步对数据库中该商品库存的判断。
 微信
微信 支付宝
支付宝
