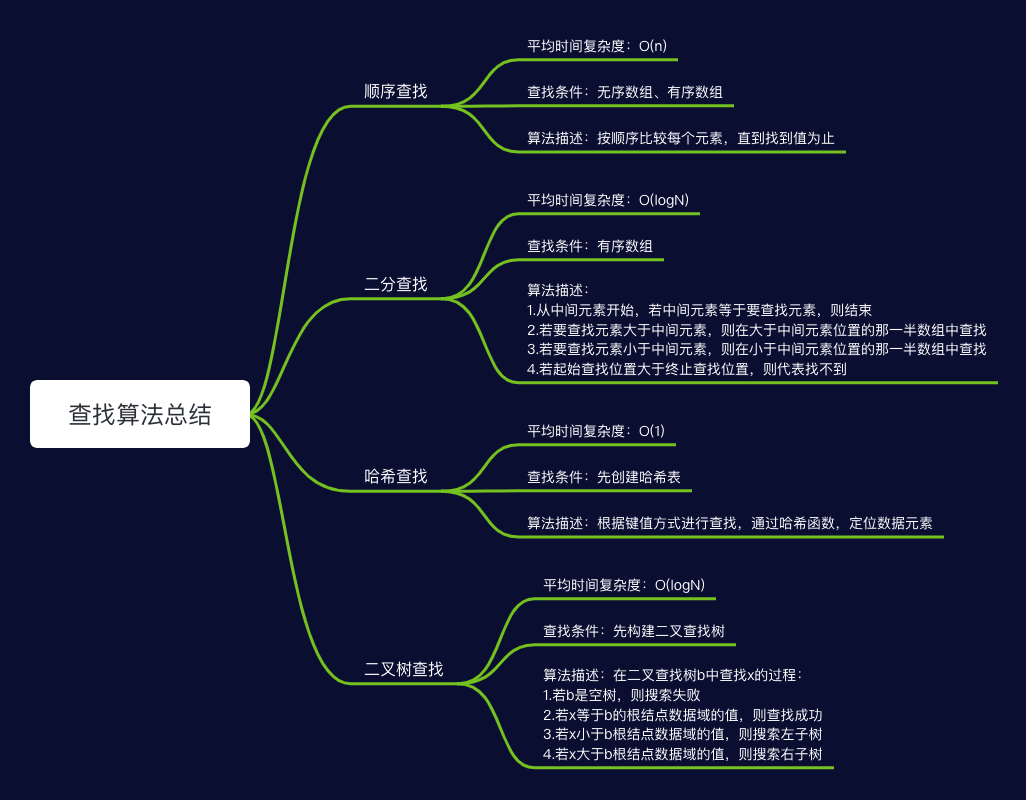
查找算法
顺序查找
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
function orderSearch(array $arr, int $needle)
{
foreach ($arr as $v) {
if ($v == $needle) {
return true;
}
}
return false;
}
|
二分查找
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
function binarySearch(array $arr, int $target)
{
$low = 0;
$high = count($arr) - 1;
while ($low <= $high) {
$mid = floor(($low + $high) / 2);
if ($arr[$mid] == $target) {
return true;
} elseif ($arr[$mid] > $target) {
$high = $mid - 1;
} else {
$low = $mid + 1;
}
}
return false;
}
function binarySearchRecursion(array $arr, int $target, int $low, int $high)
{
if ($low > $high) return false;
$mid = floor(($low + $high) / 2);
if ($arr[$mid] == $target) {
return true;
} elseif ($arr[$mid] > $target) {
return binarySearchRecursion($arr, $target, $low, $mid - 1);
} else {
return binarySearchRecursion($arr, $target, $mid + 1, $high);
}
}
|
哈希查找
代码:
1
2
3
4
| function hashSearch(array $arr, int $target)
{
return isset($arr[$target]);
}
|
树搜索
两种最常用的搜索树的方法:
树结点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class TreeNode
{
public $data = null;
public $children = [];
public function __construct(string $data = '')
{
$this->data = $data;
}
public function addChildren(TreeNode $treeNode)
{
$this->children[] = $treeNode;
}
}
|
BFS
在树结构中,根连接到其子结点,每个子结点还可以继续表示为树。在BFS中,我们从结点(主要是根结点)开始,并且在访问其他邻居结点之前,首先访问所有相邻结点。换句话说,我们在使用 BFS 时必须逐级移动。
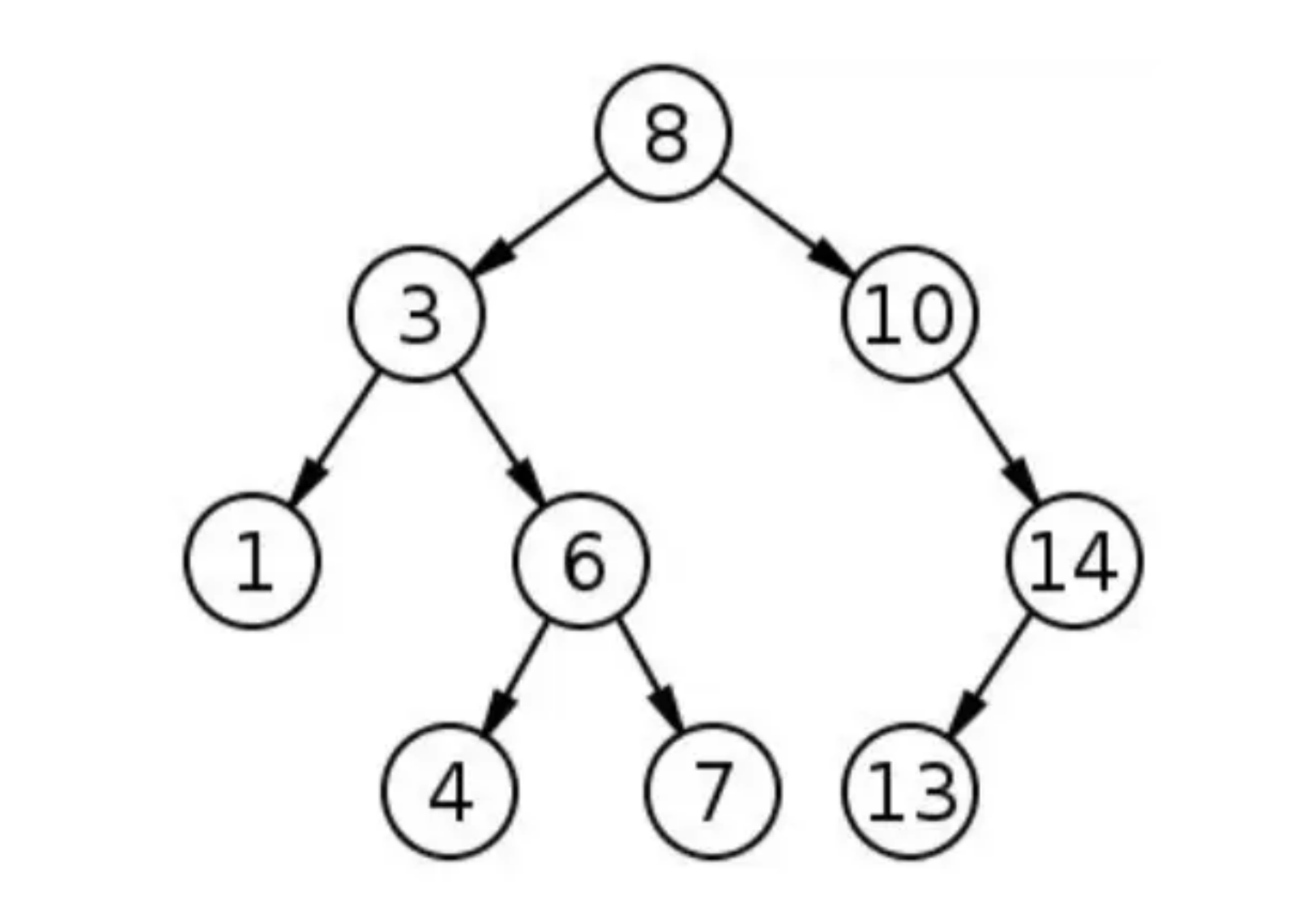
使用BFS,会得到以下的序列:
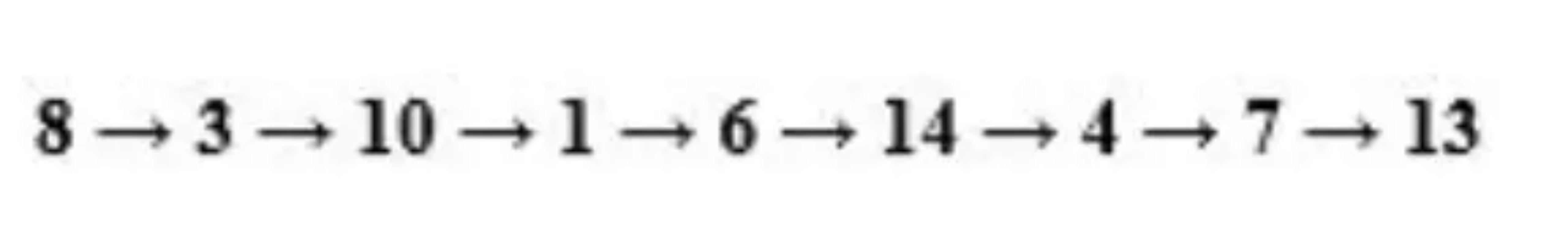
BFS代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| class Tree
{
public $root = null;
public function __construct(TreeNode $treeNode)
{
$this->root = $treeNode;
}
public function BFS(TreeNode $node): splQueue
{
$queue = new splQueue();
$visited = new splQueue();
$queue->enqueue($node);
while (!$queue->isEmpty()) {
$current = $queue->dequeue();
$visited->enqueue($current);
foreach ($current->children as $child) {
$queue->enqueue($child);
}
}
return $visited;
}
}
function displayTree($obj)
{
$count = count($obj);
foreach ($obj as $key => $node) {
if ($key == $count - 1) {
echo $node->data . PHP_EOL;
} else {
echo $node->data . "->";
}
}
}
|
如果想要查找结点是否存在,可以为当前结点值添加简单的条件判断即可。BFS最差的时间复杂度是O(|V| + |E|),其中V是顶点或结点的数量,E则是边或者结点之间的连接数,最坏的情况空间复杂度是O(|V|)
。图的BFS和上面的类似,但略有不同。 由于图是可以循环的(可以创建循环),需要确保我们不会重复访问同一结点而创建无限循环。为了避免重新访问图结点,必须跟踪已经访问过的结点。可以使用队列,也可以使用图着色算法来解决。
DFS
DFS指的是从一个结点开始搜索,并从目标结点通过分支尽可能深地到达结点。DFS与BFS不同,简单来说,就是DFS是先深入挖掘而不是先扩散。DFS在到达分支末尾时然后向上回溯,并移动到下一个可用的相邻结点,直到搜索结束。还是上面的树:
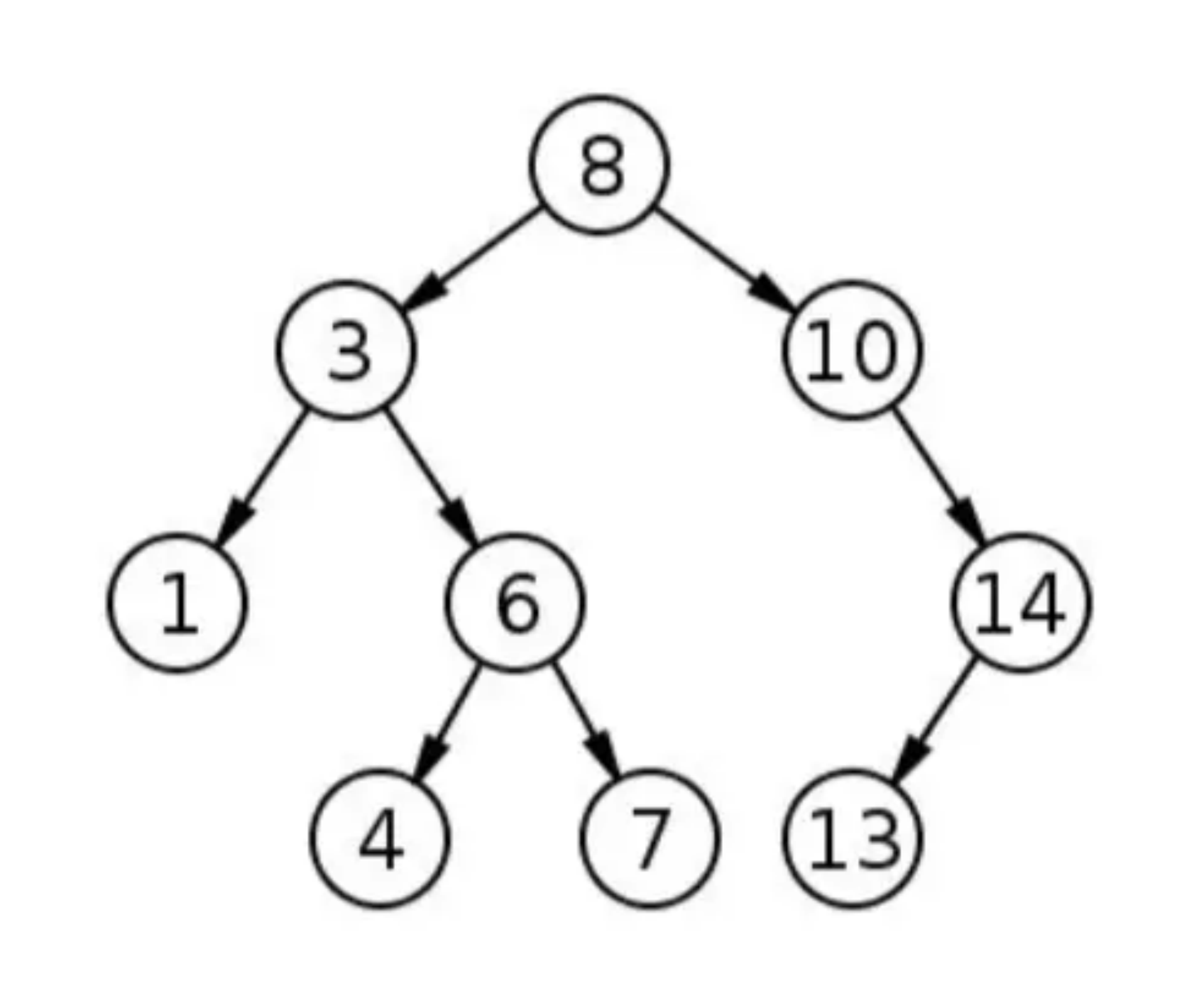
这次我们会获得不同的遍历顺序:
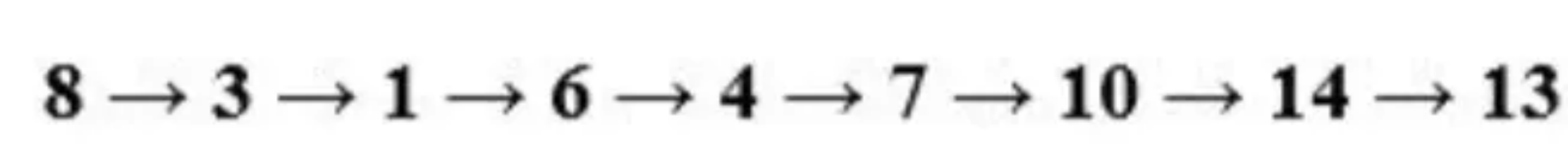
DFS代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| class Tree
{
public $root = null;
public $visited = null;
public function __construct(TreeNode $treeNode)
{
$this->root = $treeNode;
$this->visited = new splQueue();
}
public function DFS(TreeNode $node): splQueue
{
$this->visited->enqueue($node);
if ($node->children) {
foreach ($node->children as $child) {
$this->DFS($child);
}
}
return $this->visited;
}
public function DFSIterator(TreeNode $node): splQueue
{
$stack = new splStack();
$visited = new splQueue();
$stack->push($node);
while (!$stack->isEmpty()) {
$current = $stack->pop();
$visited->enqueue($current);
foreach ($current->children as $child) {
$stack->push($child);
}
}
return $visited;
}
}
function displayTree($obj)
{
$count = count($obj);
foreach ($obj as $key => $node) {
if ($key == $count - 1) {
echo $node->data . PHP_EOL;
} else {
echo $node->data . "->";
}
}
}
|
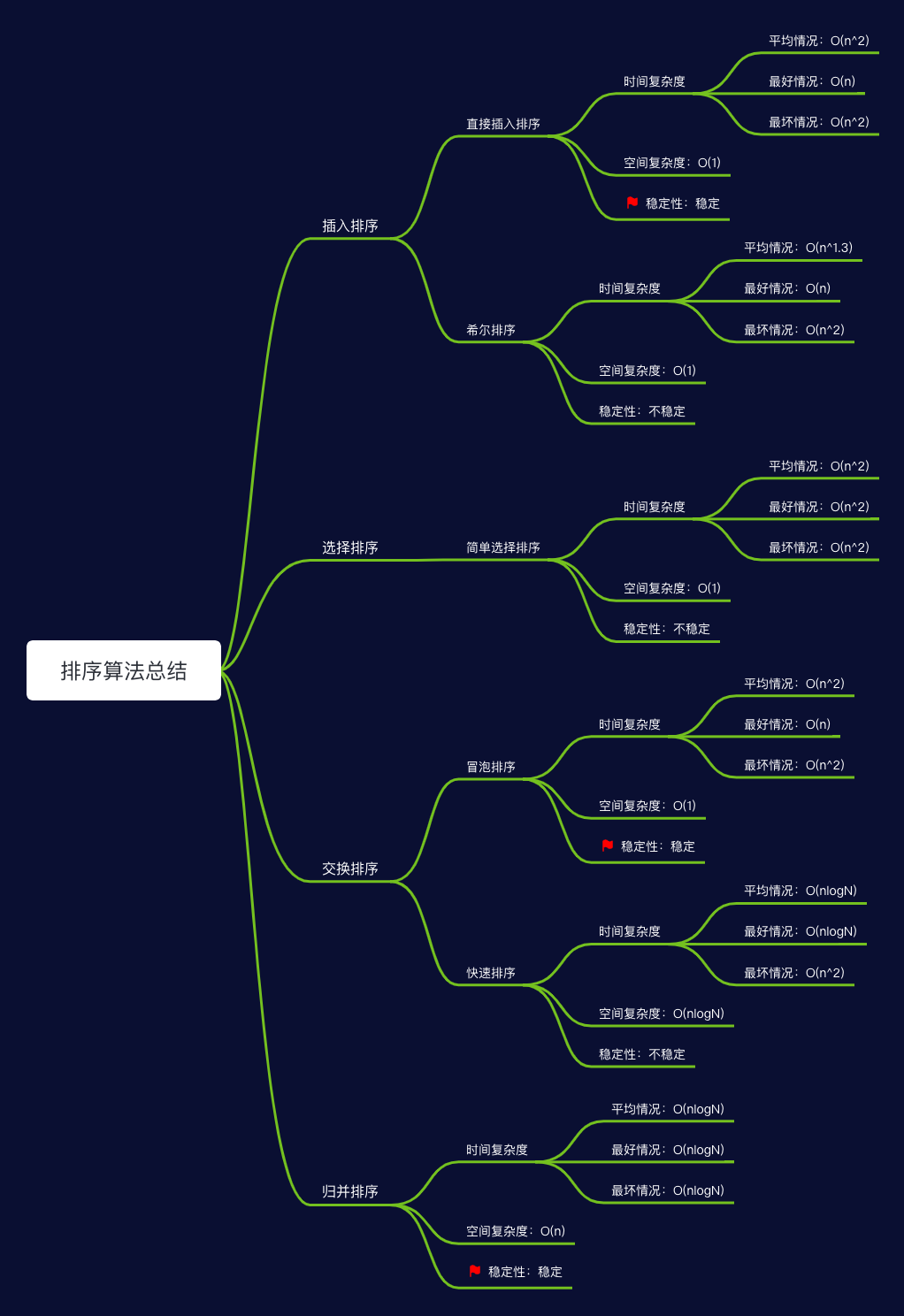
总结
排序算法
插入排序
插入排序分为:直接插入排序、希尔排序。
直接插入排序
思路:
通过构建有序序列,对于未排序序列,在已排序序列中从后向前扫描,找到相应的位置并插入。在从后向前扫描过程中,需要反复把已排序元素向后挪位,为最新元素提供插入空间,直到排序完成,如果碰到一个和插入元素相等的,那么插入的元素放在相等元素的后面。
算法描述:
a.从第一个元素开始,该元素可以认为已经被排序;
b.去除下一个元素,在已排序的元素序列中从后向前扫描;
c.如果被扫描的元素(已排序)大于新元素,将该元素移到下一位置;
d.重复步骤c,直到找到已排序的元素的小于或等于新元素的位置;
e.将新元素插入到该元素的位置后;
f.重复步骤b~e。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| function insertSort($arr)
{
$len = count($arr);
if ($len == 0) {
return $arr;
}
for ($i = 0; $i < $len - 1; $i++) {
$current = $arr[$i + 1];
$preIndex = $i;
while ($preIndex >= 0 && $current < $arr[$preIndex]) {
$arr[$preIndex + 1] = $arr[$preIndex];
$preIndex--;
}
$arr[$preIndex + 1] = $current;
}
return $arr;
}
|
希尔排序
思路:
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也成为缩小增量排序。希尔排序是把记录按一定的增量分组,对每组使用直接插入算法,随着增量逐渐减少,每组包含的关键词越来越多,当增量减少至1时,整个文件恰被分成一组,算法便终止。
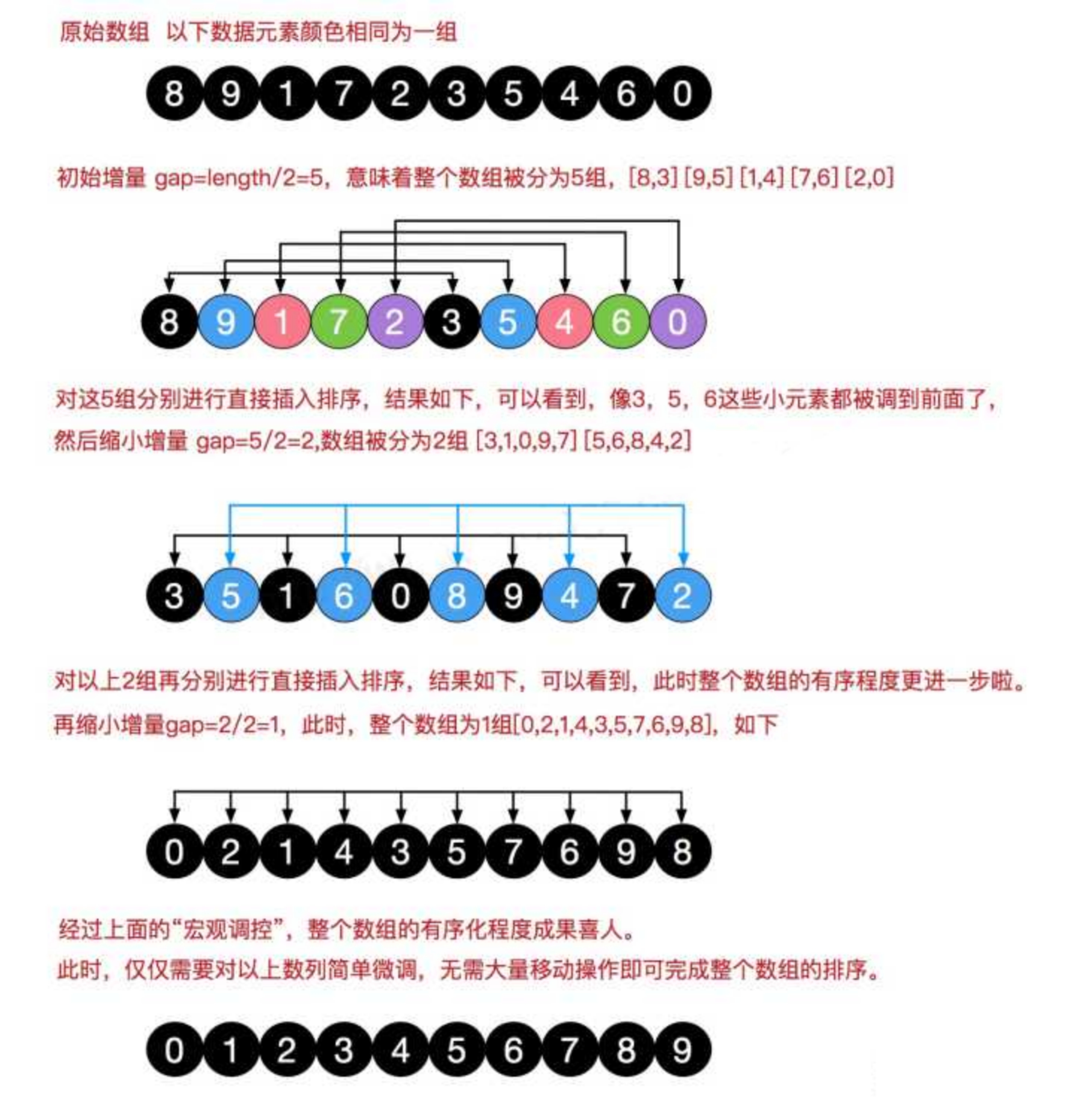
希尔排序代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| function shellSort(array $arr)
{
$len = count($arr);
if ($len == 0) {
return $arr;
}
$gap = floor($len / 2);
while ($gap > 0) {
for ($i = 0; $i < $len; $i++) {
$current = $arr[$i];
$preIndex = $i - $gap;
while ($preIndex >= 0 && $arr[$preIndex] > $current) {
$arr[$preIndex + $gap] = $arr[$preIndex];
$preIndex -= $gap;
}
$arr[$preIndex + $gap] = $current;
}
$gap = floor($gap / 2);
}
return $arr;
}
|
选择排序
选择排序分为:简单选择排序、树形选择排序和堆排序。
选择排序
思路:
在未排序的序列中找出最小(大)的元素,与序列的起始位置交换,然后再从剩余未排序的元素中继续查找最小(大)的元素,放到以排序序列的尾部,以此类推,直到所有元素排序完成
算法描述:
a.初始状态:序列为无序状态;
b.第1次排序:从n个元素中找出最小(大)的元素与第1个记录交换;
c.第2次排序:从n-1个元素中找出最小(大)的元素与第2个记录交换;
d.第 i 次排序:从n-i-1个个元素中找出最小(大)的元素与第 i 个记录交换;
e.一次类推,直到排序完成。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| function selectSort($arr)
{
$len = count($arr);
for ($i = 0; $i < $len - 1; $i++) {
$min = $i;
for ($j = $i + 1; $j < $len; $j++) {
if ($arr[$j] < $arr[$min]) {
$min = $j;
}
}
if ($min != $i) {
$tmp = $arr[$i];
$arr[$i] = $arr[$min];
$arr[$min] = $tmp;
}
}
return $arr;
}
|
总结:
总共进行n-1趟循环,每趟从剩余数组中找出最小/最大元素,并和首元素交换位置。例如i从0开始,总共进行$len-1趟循环。
交换排序
冒泡排序
思路:
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复的进行直到没有再需交换,完成排序
算法描述:
a.比较相邻的元素,如果第一个比第二个大,就交换他们两个;
b.对每一对相邻元素做同样的工作,从开始一对到结尾一对,这样在最后的元素应该就会是最大的数;
c.针对所有的元素重复以上的步骤,除了最后一个;
d.重复a~c步骤,直到排序完成
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| function bubbleSort($arr)
{
$len = count($arr);
for ($i = 0; $i < $len - 1; $i++) {
for ($j = 0; $j < $len - 1 - $i; $j++) {
if ($arr[$j] > $arr[$j + 1]) {
$tmp = $arr[$j];
$arr[$j] = $arr[$j + 1];
$arr[$j + 1] = $tmp;
}
}
}
return $arr;
}
|
总结:
总共进行n-1趟循环,每趟比较次数为(n-1-趟次)。例如i,j从0开始,总共进行$len-1趟循环,每趟比较次数为($len-1-$i)。
快速排序
思路:
将待排序记录分隔成独立的两个部分,其中一部分记录的关键字均比另一部分的关键字小,则可以分别对两部分记录继续进行排序,以达到整个序列有序。
算法描述:
a.从序列中挑出一个元素,成为“基准”;
b.重新排序数列,所有元素比基准值小的放在基准前面,所有元素比基准值大的放在基准后面。在这个分区退出之后,该基准就处于数列的中间位置,这个称为分区操作;
c.递归地把小于基准值元素的子数列和大于基准值元素的子序列排序。
快速排序代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| function quickSort($arr)
{
$len = count($arr);
if ($len <= 1) {
return $arr;
}
$base = $min = $max = [];
$baseItem = $arr[0];
foreach ($arr as $v) {
if ($v < $baseItem) {
$min[] = $v;
} elseif ($v > $baseItem) {
$max[] = $v;
} else {
$base[] = $v;
}
}
$min = quickSort($min);
$max = quickSort($max);
return array_merge($min, $base, $max);
}
|
归并排序
思路:
归并排序是一种稳定的排序方法,将已有序的子序列合并,得到完整的有序的序列,即先使每个子序列有序,再使子序列段间有序。
算法描述:
a.把长度为n的输入序列分成两个长度为n/2的子序列;
b.对这两个子序列分别归并排序;
c.将两个排序好的子序列合并成一个最终的排序序列。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| function mergeSort($data)
{
$len = count($data);
if ($len < 2) {
return $data;
}
$mid = floor($len / 2);
$left = array_slice($data, 0, $mid);
$right = array_slice($data, $mid);
return merge(mergeSort($left), mergeSort($right));
}
function merge($left, $right)
{
$result = array_merge($left, $right);
$len = count($result);
for ($index = 0, $i = 0, $j = 0; $index < $len; $index++) {
if ($i >= count($left)) {
$result[$index] = $right[$j++];
} elseif ($j >= count($right)) {
$result[$index] = $left[$i++];
} elseif ($left[$i] > $right[$j]) {
$result[$index] = $right[$j++];
} else {
$result[$index] = $left[$i++];
}
}
return $result;
}
|
总结

 微信
微信 支付宝
支付宝