
正则表达式
界定符
表示一个正则表达式的开始和结束
/[0-9]/ or #[0-9]# or {[0-9]}
正则表达式工具
regexpal
原子
可见原子
Unicode编码表中用键盘输出后肉眼可见的字符有哪些?
- 标点; “ _ ? .等等
- 英文字母数字a-z,A-Z,0-9
- 汉字、日文、阿拉伯文等其他语言文字
- ∑,∈,∮,≌等数理化公式符号
- 其他可见字符
不可见原子
Unicode编码表中用键盘输出后肉眼不可见的字符有哪些?
- 换行符\n
- 回车\r
- 制表符\t
- 空格
- 其他不可见符号
元字符
原子的筛选方式
- | 匹配两个或者多个分支选择
- [] 匹配方括号中的任意一个原子
- [^] 匹配除方括号中的原子之外的任意字符
原子的集合
- . 匹配除换行符之外的任意一个字符
- \d 匹配任意一个十进制数字,即[0-9]
- \D 匹配任意一个非十进制数字,即[^0-9]
- \s 匹配任意一个不可见原子,即[\f\n\r\t\v]
- \S 匹配任意一个可见原子,即[^\f\n\r\t\v]
- \w 匹配任意一个大小写字母、数字或下划线,即[0-9a-zA-Z_]_
- \W 匹配任意一个非大小写字母、数字或下划线,即[^0-9a-zA-Z_]
量词
- {n} 表示其前面的原子出现n次
- {n,} 表示其前面的原子最少出现n次
- {n,m} 表示其前面的原子最少出现n~m次
- * 匹配0次或者多次其之前的原子,即{0,}
- + 匹配1次或者多次其之前的原子,即{1,}
- ? 匹配0次或者1次其之前的原子,即{0,1}
边界控制与模式单元
- ^ 匹配字符串开始的位置
- $ 匹配字符串结尾的位置
- () 匹配其中的整体为一个原子
修正模式
- 贪婪匹配(u,默认)和懒惰匹配(U)
- 贪婪模式
- 匹配结果存在歧义时取其长
懒惰模式
匹配结果存在歧义时取其短
常见修正模式
U/u[默认] - 懒惰匹配/贪婪匹配
i - 忽略英文字母大小写
x - 忽略空白符
s - 让元字符’.’匹配包括换行符在内的任意字符
实战
匹配手机号: ^1[34578]\d{9}$ 或者 ^1(3|4|5|7|8)\d{9}$
email: ^[\w\.]+@\w+(\.\w+)+$
url: ^(https?:\/\/)?\w+(\.\w)+$
PHP中常用的正则表达式函数
preg_match($pattern, $subject[, array &$matches])
preg_match_all($pattern, $subject, array &$matches)
preg_replace($pattern, $replacement, $subject)
preg_filter($pattern, $replacement, $subject)
preg_grep($pattern, array $input)
preg_split($pattern, $subject)
preg_quote($str)
正则运算符转义
. \ + * ? [ ^ ] $ () {} = ! < > | : -
总结:
1.都是以preg_开头
2.除了preg_quote以外,第一个参数都是正则表达式
3.preg_match-表单验证等
4.preg_replace-非法词语过滤等
Shell编程之正则表达式
正则表达式
1.正则表达式是什么?
正则表达式是用于秒数字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找和替换操作。
2.正则表达式与通配符
l 正则表达式是用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed 等命令可以支持正则表达式。
l 通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支 持正则表达式,所以只能使用shell自己的通配符来进行匹配了。
l 通配符
¡ * 匹配任意内容
¡ ? 匹配任意一个内容
¡ [] 匹配中括号中的一个字符
3.基础正则表达式
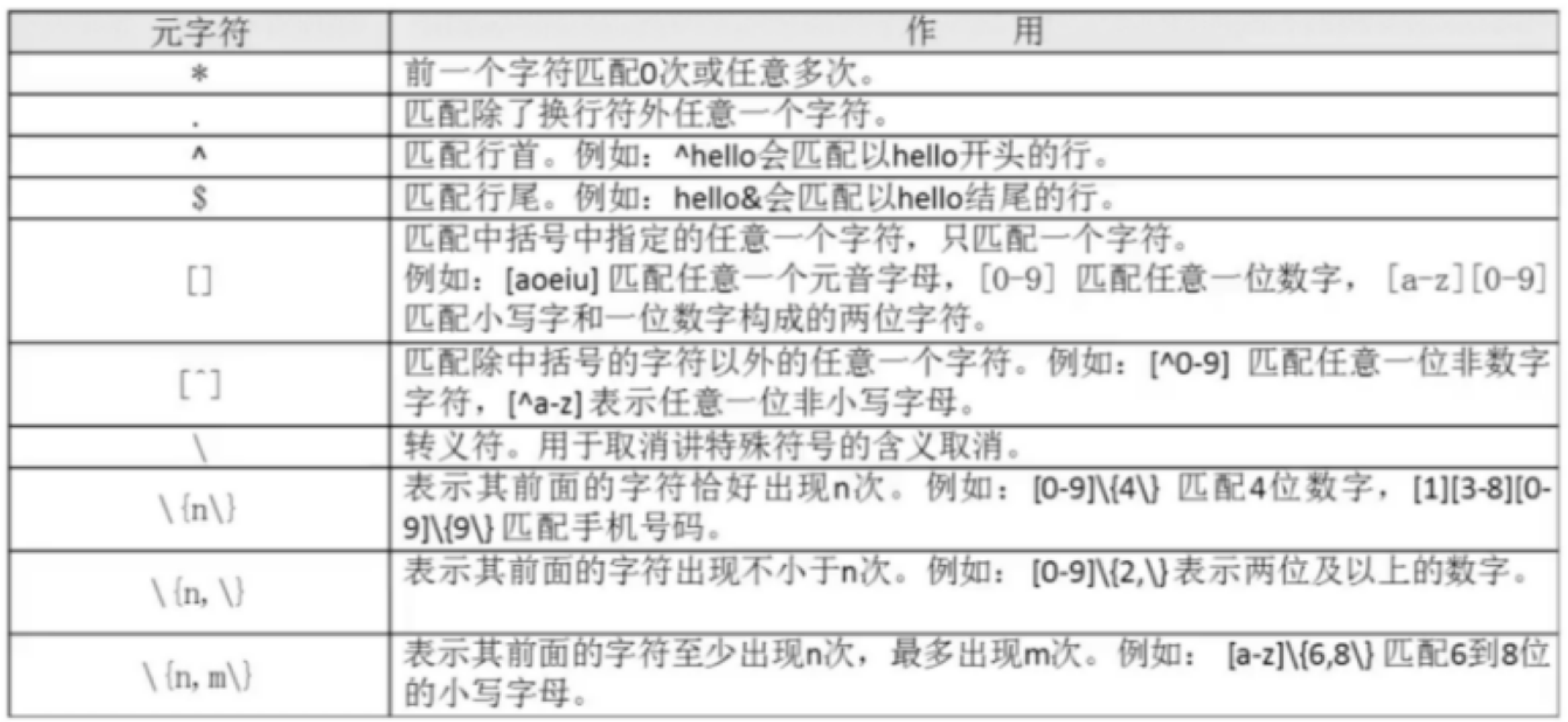
3.1“*” 前一个字符匹配0次或多次
- “a*”
匹配所有的内容,包括空白行
- “aa*”
匹配至少包含有1个a的行
- “aaa*”
匹配至少包含有连续2个a的行
- “aaaaa*”
匹配至少包含有连续4个a的行
3.2“.” 匹配出换行符之外的任意一个字符
- “s..d”
匹配在s和d之间一个会有2个字符的单词
- “s.*d”
匹配在s和d之间有任意字符
- “.*”
匹配所有内容
3.3“^” 匹配行首,“$” 匹配行尾
- “^M”
匹配以大写M开头的行
- “n$”
匹配以小写n结尾的行
- “^$”
匹配空白行
3.4“[]” 匹配中括号中指定的任意一个字符,只匹配一个字符
- “s[ao]id”
匹配s和i字母中,要么是a,要么是o
- “[0-9]”
匹配任意一个数字
- “^[a-z]”
匹配以小写字母开头的行
3.5“[^]” 匹配出中括号的字符以外的任意一个字符
- “^[^a-z]”
匹配不以小写字母开头的行
- “^[^a-zA-Z]”
匹配不以字母开头的行
3.6“\” 转义符
- “.$”
匹配使用.结尾的行
3.7“{n}” 表示其前面的字符恰好出现n次
- “a{3}”
匹配小写字母a连续出现3次的字符串
- “[0-9]{3}”
匹配包含连续的3个数字的字符串
3.8“{n,}” 表示其前面的字符出现至少n次
- “^[0-9]{3,}[a-z]”
匹配最少以连续3个数字开头的行
3.9几个例子
- [0-9]{4}-[0-9]{2}-[0-9]{2}
匹配日期格式YYYY-MM-DD
- [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}
匹配IP地址
字符截取命令
cut字段提取命令



printf命令
Printf ‘输出类型输出格式’ 输出内容
输出类型
%ns: 输出字符串。n是数字,指输出几个字符
%ni: 输出整数。n是数字,指输出几个数字
%m.nf: 输出浮点数。m和n是数字,指输出的整数位数和小数位数。如%8.2f代表共输出8位数,其中2位是小数,6位是整数。
输出格式
- \a: 输出警告声音
- \b: 输出退格键,即backspace键
- \f: 清除屏幕
- \n: 换行
- \r: 回车,即enter键
- \t: 水平制表符
- \v: 垂直制表符
printf ‘%s’ $(cat students.txt)
- 不调整输出格式
- printf ‘%s\t%s\t%s\t%s\n’ $(cat students.txt)
- 调整输出格式
在awk命令的输出中支持print和printf命令
- print: print会在每个输出之后自动加入一个换行符(Linux默认没有print命令)
- printf: printf是标准格式输出命令,并不会自动加入换行符,若需要换行,需要手动加入换行符。
awk命令
awk ‘条件1{动作1}条件2{动作2}…’ 文件名
条件(pattern):
- 一般使用关系表达式作为条件
- X>10,判断变量x是否大于10
- X>=10,判断变量x是否大于或等于10
- X<=10,判断变量x是否小于或等于10
动作(action):
- 格式化输出
- 流程控制语句
Begin
- awk ‘BEGIN{printf “This is a transcript \n”}{printf $2 “\t” $4 “\n”}’ students.txt
End
- awk ‘END{printf “The End \n”}{printf $2 “\t” $4 “\n”}’ students.txt
FS内置变量
- cat /etc/passwd | grep “/bin/sh” | awk ‘BEGIN{FS=”:”}{printf $2 “\t” $4 “\n”}’
关系运算符
- Cat students.txt | grep -v Name | awk ‘$4 >= 70{printf $2 “\n”}’
sed命令
sed是一种几乎包括在所有Unix平台(包括Linux)的轻量级流编辑器。sed主要是用来将数据进行选取、替换、删除、新增的命令。
sed [选项] ‘动作’ 文件名
- 选项:
n -n: 一般sed命令会把所有的数据都输出到屏幕,若加入此选项,则只会把经过sed命令处理的行输出到屏幕
n -e: 允许对输出数据引用多条sed命令编辑
n -i: 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
- 动作:
n a: 追加。在当前行后添加一行或多行
n c: 行替换,用c后面的字符串替换原数据行
n i: 插入。在当前行前插入一行或多行。d: 删除,删除指定的行
n p: 打印。输出指定的行
n s: 字符替换。用一个字符串替换另外一个字符串。格式为”行范围s/旧字串/新字串/g”(和vim中的替换格式类似)
行数据操作
- sed ‘2p’ student.txt
- n 查看文件的第二行
- sed -n ‘2p’ student.txt
- sed ‘2,4d’ student.txt
- n 删除第二行到第四行的数据,但不修改文件本身
- sed ‘2a hello’ student.txt
- n 在第二行后追加hello
- sed ‘2i hello’ student.txt
- n 在第二行前插入hello
- sed ‘2c furong bujige’ student.txt
- n 数据替换
- sed ‘2p’ student.txt
字符串替换
- sed ‘s/旧子串/新字串/g’ 文件名
- sed ‘3s/60/99/g’ student.txt
- n 在第三行中,将60替换成90
- sed -i ‘3s/60/99/g’ student.txt
- n sed操作的数据直接写入文件
- sed -e ‘s/fengj//g; s/cang//g’ student.txt
- n 同时把“fengj”和“cang”替换为空
字符处理命令
排序命令sort
Sort [选项] 文件名
选项
- -f: 忽略大小写
- -n: 以数值型进行排序,模式使用字符串型排序
- -r: 反向排序
- -t: 指定分隔符,默认分隔符是制表符
- -k n[,m]: 按照指定的字段范围排序。从第n个字段开始,m个字段结尾(默认到行尾)。
sort /etc/passwd
- 排序用户信息文件
sort -r /etc/passwd
- 反向排序
sort -t “:” -k “3,3” /etc/passwd
制定分隔符是“:”,用第三个字段开头,第三个字段结尾排序,即只用第三个字段排序。
sort -n -t “:” -k “3,3” /etc/passwd
统计命令wc
wc [选项] 文件名
选项
- -l: 只统计行数
- -w: 只统计单词数
- -m: 只统计字符数
 微信
微信 支付宝
支付宝